






























































Here’s a primer on generative AI, thoughts on how you can empower yourself with this tech, and an insight into how Stable Diffusion has achieved success as an open source effort.
Take a look at Figure 1. Can you guess what these three images have in common? From a quick look, you may think that it’s just the fantastical art style. What if I told you that none of them were drawn by a human artist but were generated on-the-fly within seconds by an AI model?
This is the power of generative AI — models capable of generating novel content based on a broad and abstract understanding of the world, driven by training over immense data sets. The ‘artist’ of the above images is a model named ‘Stable Diffusion’ released as open source software by the organisation Stability AI. All you have to give it is a text prompt describing the image you want in detail, and it will do the rest for you. If you’re curious, I’ve dropped example prompts that can generate the images in Figure 2.

Stable Diffusion is not the first of its kind. OpenAI’s ‘DALL-E’ beat it to the chase as it was released a few months prior. However, looking at the state of the art, it is the first generative AI model capable of image synthesis and manipulation that was released to the public as FOSS software while also being practical to adopt.
These models are not limited to images. The first generation (and possibly the most popular use case) of these models targets text generation, and sometimes more specifically code generation. Recent advances even include speech and music creation. Zooming out into a timeline with some of the major generative AI milestones (Figure 3), we see that this technology has been out for a while, but only gained monumental traction recently.
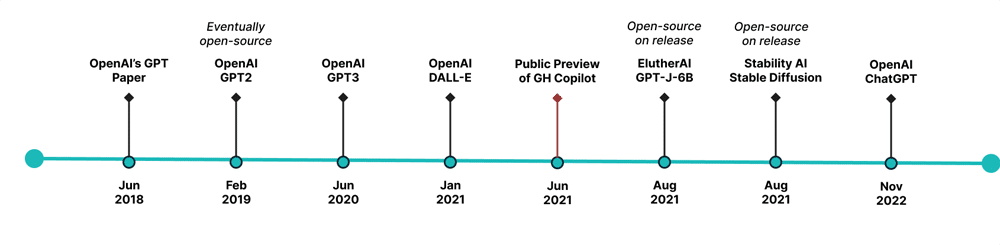
It all started with the paper titled ‘Improving Language Understanding by Generative Pre-Training’ released by OpenAI. The paper alluded to GPT (generative pretrained transformer), and laid the seed for ‘large language models’. However, generative AI started coming into the limelight with the public release of GPT-3 and DALL-E. The former is a next-generation version of the already performant GPT-2 model and the latter is an image generative model like Stable Diffusion. Their public demos and API access set ablaze the imagination of technologists across the planet. However, these implementations remain closed-source and proprietary.
Programmers were enthused and drawn towards generative AI when GitHub opened up a private preview of GitHub Copilot. Copilot utilised OpenAI Codex — an extension of GPT-3 that is trained on thousands of GitHub repositories. This specialisation allowed it to generate code on-the-fly, infer functionality of code and, more recently, automatically write test cases.
Around this time, EleutherAI created an open source model similar to GPT-3 as well with some impressive demos. It was named ‘GPT-J-6B’, the J alluding to the Google JAX framework used to develop the model.
However, nothing expanded the open source generative AI scene more than the open source release of Stability AI’s Stable Diffusion. Within hours of its release, technology forums were flooded with inspired individuals expanding the art of the possible. Several developers had built feature-complete, easy-to-use user interfaces and deployment strategies within days of its release. Some even released, modified, and optimised the model to suit specific use cases.
The release of Stable Diffusion was still not the biggest splash that generative AI had created in the world. That’s credited to the recent public demo release of ChatGPT, a purpose-built GPT-3 based model capable of holding context-aware conversations and providing an easy-to-use and familiar interface. It reached over one million users in the short span of a week, a figure that took earlier social networks months and years to achieve.
The keen-eyed among you must have noticed that Stable Diffusion isn’t the first open source generative AI model that was launched publicly, yet it somehow broke out of the mould with millions of users. A large chunk of these users self-hosted this model, integrating it deeply into their products and open source projects. So, what did they do differently?
The accessibility and wide adoption can be chalked down to two key factors.
Availability of pretrained weights
Generative AI models are often ‘deep neural networks’ with millions/billions of parameters, trained over data sets with hundreds and thousands of items, whether text or images. To look at some metrics, the cost of training GPT-3 is over 4.6 million dollars using a Tesla V100 cloud instance with training times of up to nine days. Similarly, Stable Diffusion was trained using 256 Nvidia A100 GPUs on Amazon Web Services for a total of 150,000 GPU hours, at a cost of US$ 600,000. These costs are prohibitive for individuals and even small businesses. Putting these trained models to use is more inexpensive by orders of magnitude.
Fortunately, it is possible to share the outcome of this training in the form of ‘weights’, which can be loaded by anyone who wants to use the model. This is the approach taken by GPT-J 6B and Stable Diffusion, who had weights available for download from day one. This allows individuals that have access to sufficiently powerful hardware to load up the model and put it to use.
Highly efficient architecture with lower hardware requirements for deployment
Even after obtaining a set of weights to pretrain your model, many of them require expensive GPUs like the Nvidia A100. The primary resource essential here is large reserves of VRAM, in the range of 10s of gigabytes. The VRAM is required to keep model weights in memory for reasonably fast execution. A requirement like this automatically filters out individuals with consumer-grade, yet fairly powerful GPUs.
For instance, running the full-fat version of GPT-J-6B requires upwards of 20-25GB of VRAM. Additionally, in many practical use cases, you would want to “fine-tune” the model, which involves making the model more specialised to a given use case. This is done by retraining the already trained model over a specific, curated data set. This is yet another process that requires powerful GPUs.
Stable Diffusion gets past this by utilising a novel architecture known as ‘latent diffusion’, which maps the image generation process to a smaller logical space. This allows it to run with reasonable performance on GPUs with even 8GB of VRAM, a figure easily attainable in consumer GPUs. This meant that, on release, anyone with a laptop with reasonable specifications could run the model entirely locally, resulting in no hard limits imposed on the model in terms of output filtering or the rate at which one could iterate.
You don’t need to be in the space of AI/ML to be excited by these advances. Generative AI is penetrating our lives and making us more efficient. As a developer and open source maintainer myself, I find myself using generative AI in my day-to-day tasks.
I have a significant backlog of articles that I’ve always wanted to read and gain insights from. I now find myself using ChatGPT to summarise and ask introspective questions about those articles. In the same vein, I also use it to refine and refactor code documentation, READMEs, and other artefacts in a pinch. I’ve also extensively used GitHub Copilot for writing boilerplate code and exploring unfamiliar codebases.
From a more creative perspective, I’ve begun to extensively use Stable Diffusion to provide abstract imagery for my presentations and to edit images to make minor modifications. As an experiment, I’ve been using a fine-tuned GPT-3 model and Stable Diffusion to aid my poetry writing.
In my use of generative AI, I’ve found that it’s currently far away from entirely replacing any sort of human-generated work. However, it is an invaluable asset in anyone’s toolbox that enables us to do more with less. It enables non-native speakers to write effectively, technologists to rapidly consume and summarise knowledge, and brings iterative artistry to creatives and even creatively challenged individuals. In a way, it’s open sourcing creativity!
It’s important to remember that just like other disruptive technologies, generative AI has its downsides. One of the most contentious issues is around the legality and ethical morality of using public content as training data. It’s been argued that AI shouldn’t be allowed to create derived works from the content, especially since current-generation models are incapable of appropriate attribution. From a FOSS standpoint, there has been a heavy backlash around GitHub’s use of code in open repositories to train Copilot, a paid product.
Additionally, as we employ generative AI, we must be cognizant that the models only possess an abstract understanding inferred from the training data. This means that we can’t know for sure if they are giving us the right answers. This becomes incredibly obvious when you try pushing text-based models to generate content around items that aren’t present in their training set. Most models confidently generate sentences that seem correct from a high level but are entirely inaccurate. This has led to the ban of AI-generated responses from popular Q&A sites like Stack Overflow.
In conclusion, it’s an exciting time for this field! And I for one cannot wait to see where we go in the future.
P.S.: Staying true to the spirit of ‘practice what you preach’, this article has been co-edited by ChatGPT!




















{kind=link}