






























































Data is being generated every moment of the day around the world, and can give organisations important insights into the acceptability of their products, among other things. Hadoop, a framework for distributed data analysis, is designed for the storage, processing and analysis of large datasets in a distributed computing environment. Let’s see how it works with Big Data.
Data is being generated at an unprecedented rate, which traditional data processing techniques can no longer handle. This is where Big Data comes into the picture — people, organisations, and machines generate huge amounts of structured and unstructured data. Big Data is crucial for businesses and organisations to gain insights into their operations, customer behaviour, and market trends. It can be used for applications such as fraud detection, personalised marketing, predictive maintenance, and supply chain optimisation.
The role of a Big Data engineer is to design, build, and maintain the infrastructure required to store, process, and analyse large datasets. The increasing adoption of Big Data technologies is expected to create numerous job opportunities in the field. Engineers who specialise in Big Data can work in a variety of industries, including finance, healthcare, retail, and technology. To excel in this field, one needs to be proficient in programming languages like Java, Python, and Scala. They must also possess knowledge of Hadoop, MapReduce, and be proficient in data modelling and warehousing.
Data is growing exponentially, and by 2025, it is estimated that 175 petabytes of data will be generated. In addition to social media, digital devices, online transactions, airlines, climatic data centres, hospitality data, and sensors, such massive datasets are also collected through social media. Businesses use data to gain insight into consumers’ preferences, improve product design, and increase efficiency.
Big Data is here to stay, and companies and organisations that can effectively harness its power will have a competitive advantage in the coming years.
Hadoop and Big Data
A framework for distributed data analysis called Hadoop is available for free. It is designed for the storage, processing and analysis of large datasets in a distributed computing environment. Doug Cutting and Mike Cafarella created it in 2005 for processing large amounts of web data.
Hadoop is constructed on top of the several machines in a cluster to store data using the Hadoop Distributed File System (HDFS). Its key benefit is its extensibility. Hadoop also offers fault tolerance, as data is replicated over multiple nodes, which ensures that if a node fails, data can still be accessed.
Big Data focuses on:
Velocity – How quickly data is generated, gathered and analysed
Volume – The quantity of information generated
Variety – The data type may be structured, informal, etc
Veracity – The quality and precision of the data
Value – How to use data to provide a snapshot of business processes
How HDFS works
HDFS is designed to store large files (petabytes and beyond) reliably and efficiently. In an HDFS cluster, large files are divided into smaller blocks and distributed among numerous machines. Every block is replicated on several machines to guarantee fault tolerance and data redundancy. HDFS is optimised for data streaming, rather than random access, making it well suited for applications that involve large scale data processing, such as data warehousing and log processing.
In addition to storing and retrieving data, HDFS offers numerous tools to govern and track the data stored in a cluster, which includes data compression, encryption, and access control.
How MapReduce works underneath the Hadoop system
HDFS integrates MapReduce to offer a parallel processing architecture for distributed computing. MapReduce serves as a programming model and software framework that makes it possible to process large datasets in such environments.
The core idea of MapReduce is to split large datasets into smaller segments, process each segment separately on different nodes within the cluster, and consolidate the results into a final output. Every node executes a map function that converts the key-value pairs generated from input data. The outcomes of the map function are aggregated and reduced using a reduce function, which generates a final output. This technique enables the processing of vast amounts of data in a scalable and resilient fashion.
The Hadoop ecosystem
Hadoop is a framework for distributed data analysis, which is designed to enable processing and storage. It uses distributed computing to analyse large datasets.
The Hadoop ecosystem includes various components that work together to form a comprehensive Big Data platform. Here are some of its major components.
The Hadoop Distributed File System or HDFS stores and manages immense quantities of data across an ensemble of Hadoop machines.
MapReduce is the programming model implemented in Hadoop to process large datasets. It involves dividing a large dataset into smaller chunks and independently processing each chunk in parallel across several nodes in a Hadoop cluster.
YARN (Yet Another Resource Negotiator) is the cluster management technology used in Hadoop. Its primary function is to manage and allocate resources (such as CPU and memory) across the nodes in a Hadoop cluster to applications as needed.
A data warehousing tool termed Hive delivers an SQL-like interface to manage and query data residing in Hadoop. Users can interact with tremendous data sets using typical SQL syntax because the algorithm converts queries generated by SQL into MapReduce workflows.
Pig is a sophisticated programming framework for developing MapReduce scripts. Developers can get started with Hadoop effortlessly since it supplies an elementary scripting language that abstracts away a lot of the complexity involved in developing MapReduce programs.
Spark is a powerful data processing engine capable of processing large datasets quickly and efficiently within Hadoop. It supports a wide variety of programming languages, notably Java, Python, and Scala, and is capable of analysing data in realtime or in batches.
HBase is a non-relational database that is built on top of Hadoop. It proposes quick reading and writing access to data that’s stored in Hadoop and provides optimal performance for preserving and analysing big amounts of organised information.
ZooKeeper is a distributed coordination service utilised for managing and synchronising the configuration and state of services running in a Hadoop cluster.
Installing Hadoop
At a minimum, Hadoop necessitates an operating system that operates on a 64-bit architecture and has at least 8GB of RAM.
To begin the process of installing Hadoop, obtain the latest version from the official Apache Hadoop website. After downloading the archive, extract its contents to an appropriate directory on your computer.
The next step is to edit the configuration files, specifically core-site.xml and hdfs-site.xml for configuring HDFS, and mapred-site.xml for configuring the MapReduce framework. Additionally, to enable Hadoop to function correctly, several environment variables, such as HADOOP_HOME, JAVA_HOME, and PATH, need to be set.
Before using HDFS, it must be formatted with the command bin/hdfs namenode -format. Once Hadoop is installed and configured, it can be started by running sbin/start-all.sh. To verify that Hadoop is working correctly, you can run sample MapReduce jobs provided as examples.
It is crucial to acknowledge that the installation and configuration of Hadoop can be a challenging undertaking, and the specific steps required may vary depending on your system and setup. It is advisable to refer to the official Apache Hadoop documentation and consult an experienced Hadoop administrator if you experience any difficulties.
Streaming Hadoop
To stream Hadoop, follow these steps.
1. First, make sure that you have Hadoop installed and configured correctly.
2. Create a Python script that will serve as your mapper. The mapper supports key-to-value pairs and outputs intermediary key-to-value pairs.
The mapper.py code in Python is part of a MapReduce job, and its function is to transform input data into key-to-value pairs. In the Hadoop context, the mapper takes a portion of the data and processes it to produce key-value pairs in between. These key-to-value pairs are then sent to the reducing agent for further processing.
The mapper code typically reads data from standard input (stdin), processes it in some way, and outputs key-to-value pairs to standard output (stdout), with each pair separated by a tab (\t) character. The reducer will then aggregate these intermediate results based on the keys.
In the example I provided earlier, the mapper.py code reads each line of text from standard input, splits it into individual words, and then outputs each word with a count of 1 as a key-value pair. This is a common pattern in MapReduce, where the mapper produces intermediate results that can be easily aggregated by the reducer.
mapper.py
#!/usr/bin/python
# Format of each line is:
# date\ttime\tstore name\titem description\tcost\tmethod of payment
# We want elements 2 (store name) and 4 (cost)
# We need to write them out to standard output, separated by a tab
import sys
for line in sys.stdin:
data = line.strip().split(“\t”)
if len(data) == 6:
date, time, store, item, cost, payment = data
print “{0}\t{1}”.format(item, cost)
3. To complete the task of creating a Python script that functions as a reducer, you will need to develop a code that processes intermediate key-value pairs and generates the final output. One way to do this is to use the provided code, which demonstrates how to sum the counts of each word.
The reducer.py code is an essential component of a MapReduce job in Python. Its primary role is to take the intermediate key-value pairs created by the mapper and aggregate them to generate the final output. In the context of Hadoop, the reducer is responsible for processing a set of key-value pairs and producing the final output.
Typically, the reducer code reads in key-value pairs from standard input (stdin) and aggregates the values for each key before outputting the results to standard output (stdout). The reducer’s primary function is to combine the intermediate results created by the mapper that share the same key into a single output value.
In summary, the reducer.py code in Python is an essential component of a MapReduce job that aggregates intermediate key-value pairs and generates the final output. In Hadoop, the reducer takes a set of key-value pairs, combines the intermediate results created by the mapper that share the same key, and produces the final output. The reducer typically reads in key-value pairs from standard input, aggregates the values for each key, and outputs the results to standard output.
In the example I provided earlier, the reducer.py code reads each key-value pair from standard input, extracts the word and count, and then aggregates the counts for each word. It then outputs each word along with its total count as a key-value pair.
Reducer.py
#!/usr/bin/python
import sys
oldCategory= None
totalSales = 0
# Loop around the data
# It will be in the format key\tval
# Where key is the store name, val is the sale amount
# All the sales for a particular store will be presented,
# then the key will change and we’ll be dealing with the next store
for line in sys.stdin:
data_mapped = line.strip().split(“\t”)
if len(data_mapped) != 2:
# Something has gone wrong. Skip this line.
continue
thisCategory, thisSale = data_mapped
if oldCategory and oldCategory!=thisCategory:
print “{0}\t{1}”.format(oldCategory,totalSales)
totalSales = 0
oldCategory = thisCategory
oldCategory = thisCategory
totalSales+=float(thisSale)
if oldCategory!=None:
print “{0}\t{1}”.format(oldCategory,totalSales)
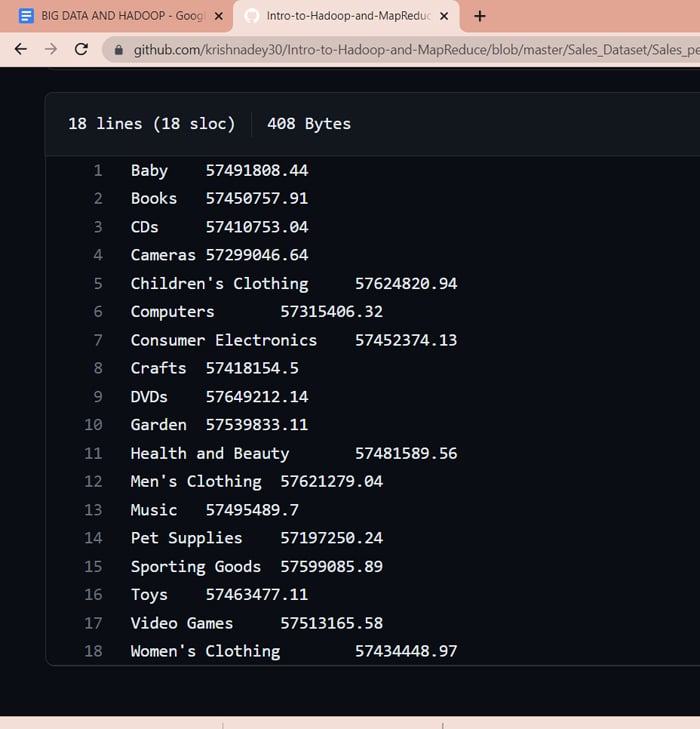
Figure 1 shows the output of the execution of the above code.
To conclude, with the increasing adoption of Big Data technologies, the demand for Big Data engineers is expected to grow exponentially, creating a plethora of job opportunities in various industries. To succeed in this field, proficiency in programming languages like Java, Python, and Scala, as well as knowledge of Big Data technologies such as Hadoop and MapReduce, is essential.

















