





























































This new architecture integrates CPU, Tensor, and Vector Units into a single processing element, offering higher performance, lower power consumption, and easier programming.
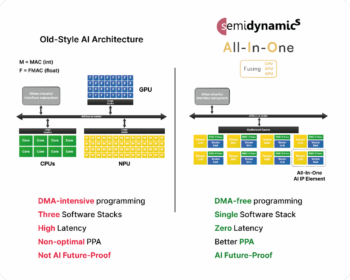
Semidynamics, a European RISC-V custom core AI specialist, has revealed Tensor Unit efficiency data for its ‘All-In-One’ AI IP running a LlaMA-2 7B-parameter Large Language Model (LLM). This new AI architecture integrates these elements into a single processing unit, combining a RISC-V core, a Tensor Unit for matrix multiplication, and a Vector Unit for activation-like computations. This architecture is DMA-free, uses a single software stack based on ONNX and RISC-V, and offers direct connectivity between elements. The result is higher performance, lower power consumption, better area utilization, and easier programming, reducing overall development costs. The Tensor and Vector Units, controlled by a flexible CPU, can deploy any current or future AI algorithm, protecting customer investments.
Large Language Models (LLMs), key in AI applications, are dominated by self-attention layers involving matrix multiplications, matrix transpose, and SoftMax activation functions. In Semidynamics’ All-In-One solution, the Tensor Unit handles matrix multiplication, while the Vector Unit manages transpose and SoftMax. Shared vector registers between these units eliminate expensive memory copies, ensuring zero latency and zero energy expenditure in data transfers. Efficient data fetching from memory into vector registers is achieved through Semidynamics’ Gazzillion Misses technology, which supports numerous in-flight cache misses.
The company tested the full LlaMA-2 7B-parameter model using its ONNX Run Time Execution Provider, calculating Tensor Unit utilization for MatMul layers.The stats indicate utilization above 80% for most shapes, even under challenging conditions. They also demonstrates Tensor Unit efficiency for large matrix sizes, maintaining performance slightly above 70% regardless of matrix size, attributed to Gazzillion technology’s high streaming data rate.
The team concluded that the All-In-One AI IP not only delivers superior AI performance but also simplifies programming with a single software stack. This makes integration into new SOC designs easier, allowing customers to benefit from better, easier-to-program silicon. The design’s adaptability to future AI/ML algorithms provides significant risk protection for customers starting silicon projects.
Roger Espasa, CEO of Semidynamics, explained the company’s novel approach. Traditional AI design utilizes a CPU, a GPU, and an NPU, connected via a bus. This setup requires DMA-intensive programming, which is slow, energy-consuming, and error-prone, necessitating the integration of three software stacks and architectures. NPUs, as fixed-function hardware, cannot adapt to future AI algorithms.

















{kind=link}