






























































In the first part of this series on dictionaries and sets, we explored the usage of dictionaries. In the second article in this series, we take a deep dive into the fascinating world of data structures to gain invaluable behind-the-scenes knowledge and help you broaden your understanding of set and hash.
A set is a collection of unique objects. Set elements need to be hashable. Frozen sets are a part of sets that are immutable.
Creating a set
Here are a few methods to create a set:
- a = set([1, 2, 3])
- b = {1, 2, 3} #Set literal
A set created using set literals is faster. Calling set constructor requires building a list and finally calling set, whereas set literal directly calls specialised BUILD_SET bytecode. Set doesn’t support index operations as it is not built as a list but by using hash.
s = {1, 2, 3}
print(s[0])
Traceback (most recent call last):
File “dict_set_sample.py”, line 44, in <module>
print(s[0])
TypeError: ‘set’ object is not subscriptable
- Frozen set
Here’s an example of an immutable version of a set:
cars = set([‘ford’, ‘renault’, ‘tata’])
print(cars)
cars.add(“kia”)
print(cars)
frozen_cars = frozenset([‘ford’, ‘renault’, ‘tata’])
print(frozen_cars)
frozen_cars.add(“kia”)
print(frozen_cars)
Output:
{‘tata’, ‘renault’, ‘ford’}
{‘tata’, ‘renault’, ‘kia’, ‘ford’}
frozenset({‘tata’, ‘renault’, ‘ford’})
Traceback (most recent call last):
File “sample.py”, line 121, in <module>
frozen_cars.add(“kia”)
AttributeError: ‘frozenset’ object has no attribute ‘add’
- Set comprehensions
Similar to any list/dict comprehensions, we have a few different types of samples explained in the blog at https://www.pythonforbeginners.com/basics/set-comprehension-in-python. Here’s an example:
curSet = set([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
newSet = {element*3 for element in curSet}
print(“The Current set is:”)
print(curSet)
print(“The Newly Created set is:”)
print(newSet)
Output:
The Current set is:
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
The Newly Created set is:
{3, 6, 9, 12, 15, 18, 21, 24, 27, 30}
Set methods are listed below:
- s.add(e) – Adds element e to s.
- s.clear() – Removes all the elements of s.
- s.copy() – Shallow copy of s.
- s.discard(e) – Removes element e from s if it is present.
- s.pop() – Removes element and returns an element from s, raising KeyError if s is empty. However, the pop method removes the last element of the set and the set itself is not ordered. One needs to be cautious using this as any element could be removed.
- s.remove(e) – Removes element e from s, raising KeyError if e is not in s.
- s.isdisjoint(z) – Returns True if no elements are common in s and z.
- Sort
sorted(s) gives the sorts the set values, and returns the ordered output. For example:
s = {3, 4, 2, 1}
print(sorted(s))
[1, 2, 3, 4]
- Set operators
As the name suggests, sets are ideally useful for performing set operations. Set operations as infix operators are useful to make the code easier to read and analyse.
Examples are:
- s & z: s.__and__(z) – Intersection of s and z
- s | z: s.__or__(z) – Union of s and z
- s – z: s.__sub__(z) – Difference between s and z
- s ^ z: s.__xor__(z) – Symmetric difference
- e in s: s.__contains__(e) – Element e is present in s
- s < z: s.__le__(z) – Validates s is a subset of the z set
- s <= z: s.__lt__(z) – Validates s is proper subset of the z set
- s > z: s.__ge__(z) – Validates s is a super set of the z set
- s >= z: s.__gt__(z) – Validates s is proper super set of the z set
- s =& z: Intersection of s and z; s is updated
- Performance
Here’s a sample performance validation to check the values:
def return_unique_values_using_list(values):
unique_value_list = []
for val in values:
if val not in unique_value_list:
unique_value_list.append(val)
return unique_value_list
def return_unique_values_using_set(values):
unique_value_set = set()
for val in values:
unique_value_set.add(val)
return unique_value_set
import time
id = [x for x in range(0, 100000)]
start_using_list = time.perf_counter()
return_unique_values_using_list(id)
end_using_list = time.perf_counter()
print(“time elapse using list: {}”.format(end_using_list - start_using_list))
start_using_set = time.perf_counter()
return_unique_values_using_set(id)
end_using_set = time.perf_counter()
print(“time elapse using set: {}”.format(end_using_set - start_using_set))
Output:
time elapse using list: 83.99319231199999
time elapse using set: 0.01616014200000393
As we can see, when it comes to the performance between set and list, set wins with a big margin. The time complexity for querying is O(1), while space complexity for storing is O(n).
Hash and hash tables
Hash and hash tables are two different but inter-related concepts.
- Hash: This is a function to generate a unique value for different sets of values.
- Hash table: This is a data structure to implement dictionaries and sets. Basically, it’s a data structure to save keys and values.
- Hash
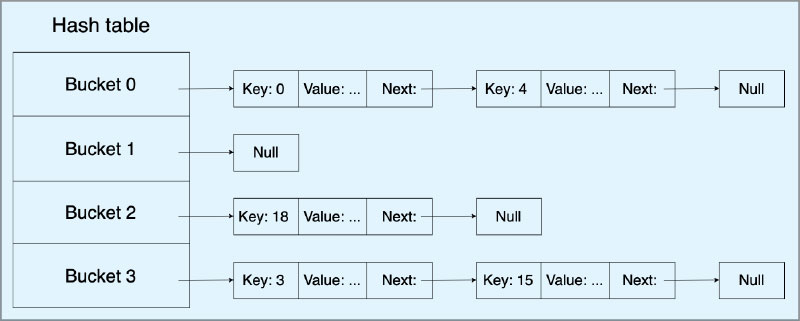
A hash value for the given key to the hash function will always return the same hash value. The efficiency of the hash function lies in turning the key into an index of the list. Hence, an effective hash function and list can determine the index of data in the list without a search. Keys must be hashable objects.
For user defined dict class, if __eq__ method is implemented it requires __hash__ also to be implemented, as it should make a == b return True and hash(a) == hash(b) return True as well.
In Python 3, if you override __eq__, it automatically sets __hash__ to None, making the object unhashable. We need to manually override __hash__ to make it hashable again.
In Python we have a built-in hash function, which is used to generate a unique value for a different set of values. Here’s an example of getting the same hash key running in the same program; the results differ completely even if there is a small variation.
print(hash(“Lorem”)) print(hash(“Lorem”)) print(hash(“Loren”)) 5675358576591581973 5675358576591581973 1733253194914647111
In general, each rerun will produce random values (as given below). This is expected behaviour and is used as a countermeasure against Denial-of-Service (DoS) or hash flooding. Hash flooding occurs when the attacker knows that for the list of keys the hash function returns the same hash bucket, causing a collision. If the language does not provide a randomised hash function or the application server does not recognise attacks using multi-collisions, an attacker can degenerate the hash table by sending lots of colliding keys. The algorithmic complexity of inserting ‘n’ elements into the table then goes to O(n**2), making it possible to exhaust hours of CPU time using a single HTTP request (see https://ocert.org/advisories/ocert-2011-003.html).
>> /usr/bin/python3 -c ‘print(hash(“Lorem”))’ 3856737851614672944 >> /usr/bin/python3 -c ‘print(hash(“Lorem”))’ 3400600052546168698 >> /usr/bin/python3 -c ‘print(hash(“Lorem”))’ 3757617178999059249
At the time of writing this, the siphash24 algorithm was used to generate hash by built-in hash. This was designed to prevent DoS hash flooding. Along with SipHash, random salt was used.
In Python 3.3, a random salt value is included when computing hash codes for str, bytes, and datetime objects, as documented in issue 13703 (hash collision security issue). The salt value is constant within a Python process but varies between interpreter runs. With PEP-456, Python 3.4 adopted the SipHash cryptographic function to compute hash codes for str and bytes objects. The random salt and SipHash are security measures to prevent DoS attacks. Check the reference for Python 3.8.9 at https://en.wikipedia.org/wiki/SipHash.
import sys print(sys.hash_info.algorithm) siphash24
To disable hash randomisation by setting a fixed seed value through the PYTHONHASHSEED environment variable, use the following:
>> PYTHONHASHSEED=1 /usr/bin/python3 -c ‘print(hash(“Lorem”))’ 440669153173126140 >> PYTHONHASHSEED=1 /usr/bin/python3 -c ‘print(hash(“Lorem”))’ 440669153173126140 >> PYTHONHASHSEED=1 /usr/bin/python3 -c ‘print(hash(“Lorem”))’ 440669153173126140
Instances of built-in mutable types—like lists, sets, and dicts—aren’t hashable. Only immutable objects are hashable (keys alone).
>> /usr/bin/python3 -c ‘hash([1, 2, 3])’ Traceback (most recent call last): File “<string>”, line 1, in <module> TypeError: unhashable type: ‘list’
Small integers of hash values are equal to themselves, which is an implementation detail that CPython uses for simplicity and efficiency. The hash values don’t matter as long as you can calculate them in a deterministic way.
print(hash(5)) print(hash(500000)) print(hash(50000000000)) print(hash(500000000000000000000)) print(hash(5000000000000000000000000000000)) print(hash(50000000000000000000000000000000000000000)) Output: 5 500000 50000000000 1937910009842106584 20450418580029579 24958392007006097 >>>[hash(i) for i in range(4)] [0, 1, 2, 3] Comment: cpython implementation dictobject.c
This isn’t necessarily bad! To the contrary, in a table of size 2**i, taking the low-order i bits as the initial table index is extremely fast, and there are no collisions at all for dicts indexed by a contiguous range of ints. So, this gives better-than-random behaviour in common cases, and that’s very desirable.
To define a hash function for an object, define the __hash__ method.
class HashToOne(object): def __hash__(self): return 1 HTO = HashToOne() print(hash(HTO)) Output: 1
To set an object as not hashable, set __hash__ to None.
class NotHashable(object): __hash__ = None NH = NotHashable() print(hash(NH)) Output: Traceback (most recent call last): File “dict_sample.py”, line 94, in <module> print(hash(NH)) TypeError: unhashable type: ‘NotHashable’
Define your own hash with caution, as it could easily mislead the actual implementation of datatypes and one may encounter subtle issues. Read the blog at https://www.asmeurer.com/blog/posts/what-happens-when-you-mess-with-hashing-in-python/ to understand the challenges and their solutions.
- Hash tables
Hash tables are the engines behind dicts and sets making it quicker to achieve O(1). Here only the keys must be hashable. Each position in the hash table is called a bucket.
Figure 1 gives one way to handle a hash collision but there are several other ways, which we will discuss later.
Once the hash value is generated, it’s passed through a mathematical process to get the bucket number placed. Here’s the process.
- Simple version: bucket_index = hash(key) % number_of_buckets
- Yet another version: bucket_index = hash(key) % prime_number
Hash table is initially built as a sparse array that usually comes with half or one-third empty cells.
- Sample dict: d = {‘timmy’: ‘red’, ‘barry’: ‘green’, ‘guido’: ‘blue’}
- Code structure:
struct dict {
long num_items;
dict_entry* items; /* pointer to array */
}
struct dict_entry {
long hash;
PyObject* key;
PyObject* value;
}
Stored as:
items = [[‘--’, ‘--’, ‘--’],
[-8522787127447073495, ‘barry’, ‘green’],
[‘--’, ‘--’, ‘--’],
[‘--’, ‘--’, ‘--’],
[‘--’, ‘--’, ‘--’],
[-9092791511155847987, ‘timmy’, ‘red’],
[‘--’, ‘--’, ‘--’],
[-6480567542315338377, ‘guido’, ‘blue’]]
After Python 3.6 the structure was changed to make it compact and memory efficient.
- Code structure:
struct dict {
long num_items;
// new PyPy dictionary is split in two arrays
variable_int *sparse_array;
dict_entry* compact_array;
}
struct dict_entry {
long hash;
PyObject *key;
PyObject *value;
}
Stored as:
sparse_array = [None, 1, None, None, None, 0, None, 2]
compact_array = [[-9092791511155847987, ‘timmy’, ‘red’],
[-8522787127447073495, ‘barry’, ‘green’],
[-6480567542315338377, ‘guido’, ‘blue’]]
In the latest code structure change, the compact_array stores all the items in the order of insertion maintained in the dictionary, while sparse_array is a half to two-thirds full array of integers (https://morepypy.blogspot.com/2015/01/faster-more-memory-efficient-and-more.html).
The integers themselves are of the smallest size necessary for indexing the compact_array. So, if compact_array has less than 256 items, then sparse_array will be made of bytes; if less than 2^16, it’ll be two-byte integers; and so on. This design saves quite a bit of memory.
For example, on 64-bit systems we can use indexing of more than 4 billion elements but hardly ever do so; and for small dicts, the extra sparse_array takes very little space. For example, a 100 element dict, on average for the original design on 64-bit, would be: 100 * 12/7 * WORD * 3 =~ 4100 bytes, while on the new design it’s 100 * 12/7 + 3 * WORD * 100 =~ 2600 bytes. This is quite a significant saving.
With the reduced memory footprint, we can also expect better cache utilisation. Only the data layout needs to change — all the hash table algorithms stay the same, and there is no change in hash functions, search order or collision statistics. If the hash table is filled, it is copied to a new location or resized for extra space (just like once the list grows it will be resized).
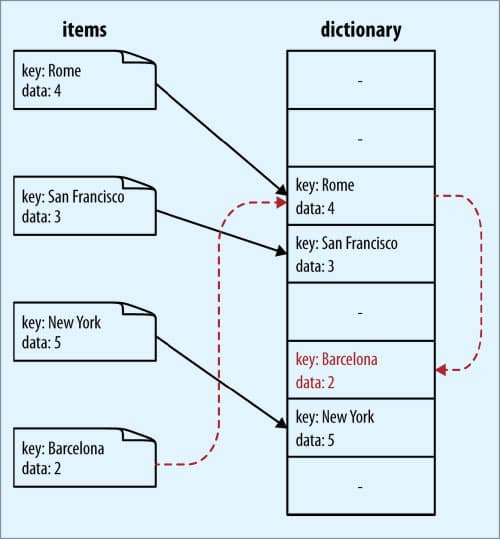
Hash collision
When the hash function gives the same value for different keys, it is known as hash collision. Here are a few methods to address hash collision.
Open addressing: Spread the collided values in a predictable way that lets you retrieve them later. You can use the following algorithms:
- Cuckoo hashing
- Double hashing
- Hopscotch hashing
- Linear probing
- Quadratic probing
- Robin Hood hashing
Closed addressing: Keep the collided values in a separate data structure to search through. This is also known as separate chaining.
Coalesced hashing: This combines the ideas behind both open and closed addressing into one algorithm.
- Insertion
Each item saved in a hash table contains two fields for hash mapping — a reference to the key and a reference to the value of the item. For sets, it is only the latter.
To insert the key into the dict, the hash value is calculated using the built-in hash() function. The hash value then performs an ‘and’ operation for creating a mask value so that it turns into an effective index to fit in an array (or bucket).
If we have allocated 8 blocks of memory and our hash value is 28975, we consider the bucket at index 28975 & 0b111 = 7; however, if the dictionary has grown to require 512 blocks of memory, then the mask becomes 0b111111111 and we consider the bucket at index 28975 & 0b11111111.
Check if the returned index is already in use; if not, insert the key and the value into the block of memory. If already in use and the key matches the given key, update the value.
If there is a collision, i.e., the hash function has generated the same hash value for two different keys, a new index simple linear function is used, which is called probing.
hash collision (perturb)
- Search
To find the position where they should be based on the hash value, compare the hash value and key of the element in this position to the hash table to see if they are equal to the element that needs to be found. If equal, return directly; if they are not, then continue to search until a slot is found or an exception is thrown.
- Deletion
For the delete operation, Python temporarily assigns a special value to the element at this position marking it as deleted. Order is preserved and then deleted from the compact array when the hash table is resized and many entries need to be cleared. It also reindexes the sparse array, as the positions have changed.
The occurrence of hash collisions tends to reduce the speed of dictionary and set operations. In order to ensure efficiency, the dictionary and the hash table in the collection are usually guaranteed to have at least two-thirds of the remaining space.
With the continuous insertion of elements, when the remaining space is less than two-thirds, Python will regain a larger memory space and expand the hash table. However, in this case, all element positions in the table will be rearranged.
Although the hash collision and the adjustment of the size of the hash table will slow down the speed, this happens very rarely. Therefore, on average, this can still ensure that the time complexity of insert, find, and delete is O(1).
Dicts have significant memory overhead. Even an empty dictionary occupies more memory than lists or tuples. Here’s a sample:
import sys
sample_dict = {}
print(sample_dict, “ size of empty dict”, sys.getsizeof(sample_dict), type(sample_dict))
sample_list = list()
print(sample_list, “ size of empty list”, sys.getsizeof(sample_list), type(sample_list))
Output:
{} size of empty dict 64 <class ‘dict’>
[] size of empty list 56 <class ‘list’>
Though dicts require additional storage they ensure better performance. We can optimise them and this is a continuous process. One just needs to remember that optimisation is the altar where maintainability is sacrificed. Modifying the dict while iterating is not a good idea.
Set and frozen set types are also implemented with a hash table, except that each bucket holds only a reference to the element. If there is a slight variation in dict algorithms, we need to perform lookups, whereas sets are used to save unique objects.
As mentioned earlier, dictionaries and sets outperform lists and tuples, especially when it comes to search, addition, and deletion operations. Dictionaries utilise hash tables to achieve constant time complexity, making them highly efficient. Sets and dictionaries share similarities, with the only difference being that sets do not have key-value pairs and consist of unique and unordered element combinations.
Lastly, let’s give a round of applause to Python’s core developers, researchers, and other engineers who work behind the scenes to improve Python’s efficiency, security, and overall performance.

















{kind=link}