






























































MLOps helps enterprises develop, deploy, and manage machine learning systems that are reliable, scalable, and production ready.
Enterprises have moved past the era of siloed AI experiments and into a phase of true operational reliance. The goal is to automate and stabilise the entire lifecycle of a machine learning model and leverage autonomous agents that drive revenue, safety, and customer trust.
According to a recent study from Innovatics, nearly 87% of machine learning models fail during deployment. They never reach production. Manual monitoring leads to undetected model drift and risk. Also, only 54% of AI projects advance from pilot to production at best. MLOps tools and technologies address these failures. Enterprises are investing billions trying to solve the ML model deployment crisis.
MLOps is the standardised framework that unifies data science, DevOps, and governance to ensure models are not just built, but are reliable, compliant, and cost-effective at scale. It bridges the gap between the people who build the models and those who run the business. Its pillars are:
Machine learning
Focused on model architecture, feature engineering, and hyperparameter tuning.
DevOps
Focused on CI/CD (continuous integration/continuous deployment), infrastructure-as-code, and system uptime.
Data engineering
This focuses on the ‘plumbing’ — it addresses ingesting, cleaning, and versioning the massive datasets required to train models.
According to Grant View Research, the global MLOps market is projected to grow from US$ 2.19 billion (2024) to US$ 16.6 billion by 2030 at a CAGR of 40.5%. As per a report from Innovatics, MLOps spending in the US grew from nearly zero to over US$ 2 billion in 2024, and is projected to reach US$ 17-40 billion by 2030.
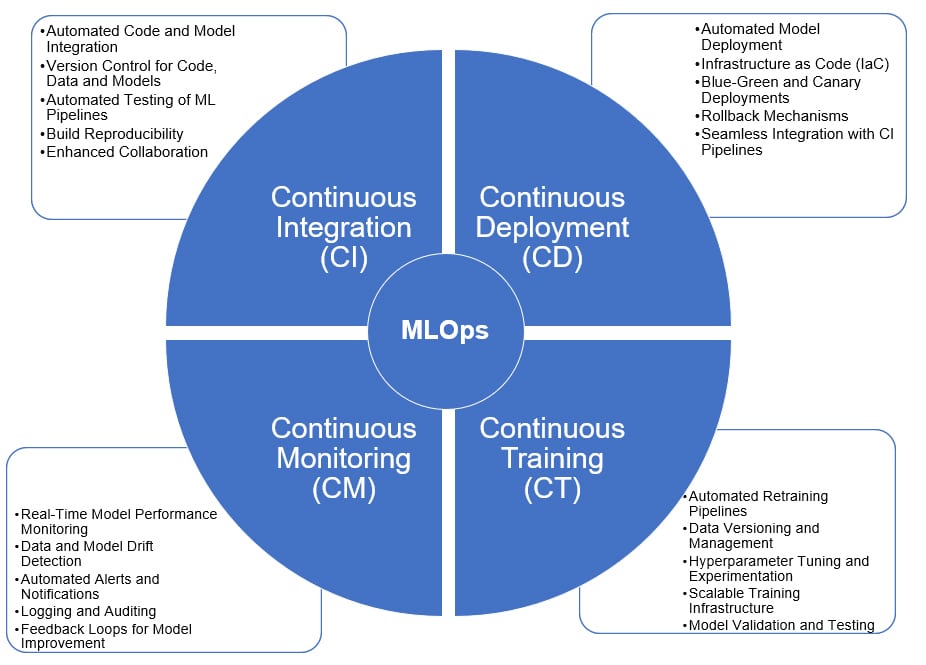
Core principles of MLOps
MLOps enables automation across the ML lifecycle, reducing errors and accelerating delivery, while aligning data scientists, ML engineers, data engineers, and DevOps teams around shared processes and tools.
Four continuous practices form the backbone of MLOps.
Continuous integration (CI) in MLOps
This automates the merging of code and models into a shared repository while maintaining strict version control. CI covers:
- Automated code and model integration: Merges code changes and ML models into a shared repository seamlessly.
- Version control for code, data and models: Utilises tools like Git, DVC or MLflow to track changes.
- Automated testing of ML pipelines: Implements unit tests, integration tests and validation tests for data and models.
- Build reproducibility: Ensures that builds can be replicated consistently across environments.
- Enhanced collaboration: Facilitates teamwork between data scientists, engineers and stakeholders.
Continuous deployment (CD) in MLOps
This moves models safely into production using strategies like blue-green or canary deployments to minimise risk. CD covers:
- Automated model deployment: Deploys machine learning models to production environments automatically.
- Infrastructure as Code (IaC): Uses Terraform or Kubernetes for scalable, reproducible deployments.
- Blue-green and canary deployments: Implements strategies for safe and incremental model releases.
- Rollback mechanisms: Enables quick rollback to previous model versions in case of issues.
- Seamless integration with CI pipelines: Ensures smooth transition from integration to deployment phases.
Continuous training (CT) in MLOps
This regularly updates models with fresh data to maintain their predictive power automatically. It covers:
- Automated retraining of pipelines: Schedules and triggers model retraining based on data updates or performance metrics.
- Data versioning and management: Tracks and manages datasets using tools like DVC or Delta Lake.
- Hyperparameter tuning and experimentation: Automates optimal parameter search with frameworks like Optuna or Hyperopt.
- Scalable training infrastructure: Leverages cloud resources or distributed computing for efficient training.
- Model validation and testing: Ensures new models meet performance and quality standards before deployment.
Continuous monitoring (CM) in MLOps
This tracks real-time metrics such as accuracy and latency using tools to identify issues immediately. It covers:
Real-time model performance monitoring: Tracks metrics using tools like Prometheus or Grafana.
Data and model drift detection: Identifies changes in data distribution or model performance.
Automated alerts and notifications: Sets up alerts for anomalies or performance degradation.
Logging and auditing: Maintains logs for compliance and troubleshooting.
Feedback loops for model improvement: Uses monitoring insights for retraining and deployment cycles.
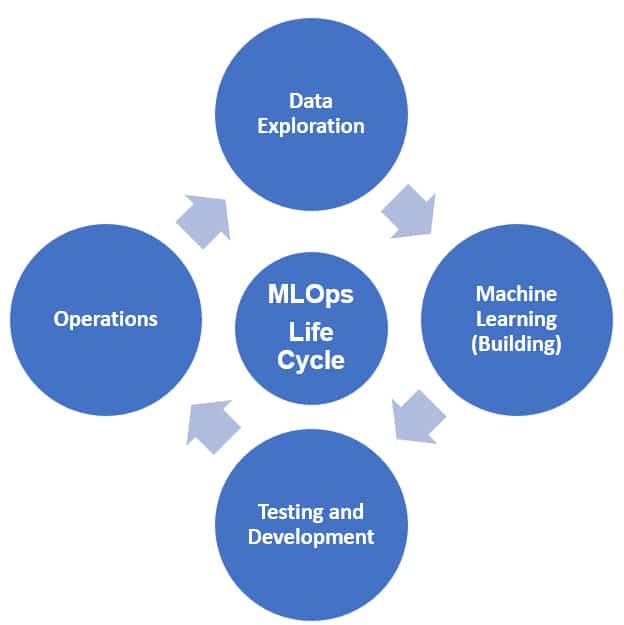
MLOps lifecycle
The process of building and maintaining an ML model is divided into four key functional areas.
Data exploration
This initial phase occupies 30-40% of the project time. It involves collecting, transforming, and validating data to ensure it is ready for training.
Machine learning (building)
This involves selecting the right algorithms and optimising model performance for the specific business use case.
Testing and development
Rigorous validation is done in this phase using techniques like cross-validation to ensure the model solves the problem without creating new ones.
Operations
This involves deploying the model as a service and monitoring its performance in a production environment.
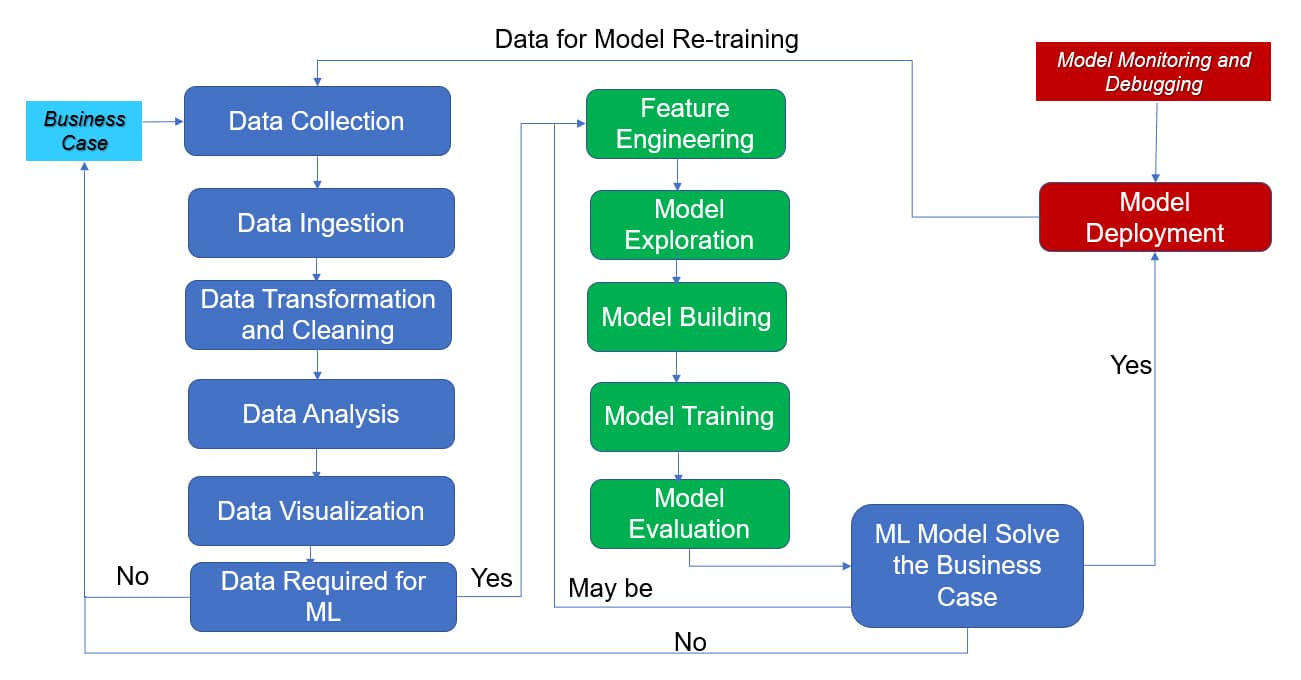
MLOps framework for enterprise adoption
The MLOps framework is designed to bridge the gap between model development and production. It focuses on automation, monitoring, and standardising the ML lifecycle. The steps involved are:
Business case
In this step, the usage of ML and how it should be leveraged to solve the business problem is clearly articulated.
Data collection
Raw data is identified and gathered from all relevant sources as part of this step – for example, EHR data, lab results, prior admissions, demographics, claims, etc.
Data ingestion
In this step, data is moved from source systems into ML platforms like data lakes, warehouses, or feature stores. An example is batch ingestion of nightly ETL jobs from operational databases into a lakehouse.
Data transformation and cleaning
Here, raw and messy data is turned into structured, usable data (such as removing duplicates of the same patient visits recorded twice).
Data analysis
This involves exploratory data analysis (EDA) to understand distributions, relationships, and issues. An example is a correlation analysis between features and the target.
Data visualisation
Visual storytelling makes data patterns and issues understandable to stakeholders – for example, visualising customer churn by tenure and product usage.
Feature engineering
In this step, meaningful input variables (features) are created from raw data. An example is the number of patient admissions in a hospital in the last 12 months.
Model exploration
This involves trying different model families and approaches to see what fits best – for example, LSTMs for time-series and Transformers for text in deep learning.
Model building
The chosen model(s) are formalised into reproducible code and pipelines, such as implementing a training script that reads from the feature store, trains, and logs metrics.
Model training
The training process is run at scale, often multiple times, in this step. An example is training on millions of patient records to predict readmission.
Model evaluation
This assesses how well the model performs and whether it’s fit for its purpose – for example, fairness and performance across age, gender, region, or other sensitive groups.
Model deployment
The model is made available to real users and systems in this step. An example is a REST endpoint that returns readmission risk when given patient data in API deployment.
Model monitoring and debugging
This involves ongoing oversight of the model in production such as monitoring prediction drift.
| Parameter | DevOps | MLOps |
| Purpose | General software development and IT operations | Machine learning model development, deployment and monitoring |
| Collaboration | Developers, IT operations and security teams | Data scientists, ML engineers, DevOps engineers and analysts |
| Roles | DevOps engineers, system admins, software developers | MLOps engineers, data scientists, machine learning engineers |
| Key tools | Jenkins, Docker, Kubernetes, Ansible, Terraform | ML flow, DVC, Kubeflow, TFX, Airflow |
| Main component | Code | Code + Data + Model |
| Testing | Unit and integration tests | Back testing, drift detection, and bias audits |
| Lifecycle management | Focuses on app code lifecycle and infrastructure | Focuses on data, model lifecycle and continuous retraining |
| Primary focus | Code delivery, system automation and reliability | Data versioning, model reproducibility and performance |
| Deployment | Single software version | A/B testing and shadow deployments |
| Maintenance | Bug fixes | Retraining and fine-tuning |
| Performance monitoring | Primarily monitors system and application performance | Monitors model drift, accuracy and impact on real world data |
| Scalability | Infrastructure scaling for application needs | Scaling ML pipelines and model deployment |
Table 1: DevOps and MLOps – a comparison
Role of an MLOps engineer
MLOps engineers acts as the bridge between development and operations. Their roles focus on:
Foundational DevOps skills
Managing the operation and deployment aspects of the ML workflow using traditional software engineering practices.
Standardised model development
Implementing industry best practices to ensure models are reproducible, scalable, and compliant with organisational standards.
Pipeline management
Designing and managing end-to-end pipelines from data ingestion to automated model deployment, so that data scientists can focus on higher-level tasks.
Open source MLOps platforms
A modern MLOps stack combines traditional DevOps tools with specialised machine learning platforms (Table 2).
Here’s a brief description of these tools.
Apache NiFi
This visual data-flow tool is designed for moving and transforming data between systems. It supports drag-and-drop pipelines, real-time streaming, and strong data provenance. NiFi excels in regulated environments because every data movement is tracked and auditable.
Airbyte
Airbyte provides open source ELT connectors for databases, SaaS apps, and APIs. It offers 300+ ready-to-use connectors and a simple YAML-based configuration model. Its modular design makes it easy to extend and integrate into modern data platforms.
Singer (Taps & Targets)
This tool defines a simple, open standard for data extraction and loading. Taps pull data from sources, and Targets load it into destinations. It’s lightweight, scriptable, and ideal for custom or niche integrations.
Apache Kafka
Kafka is a distributed event-streaming platform used for real-time data ingestion and messaging. It provides durable logs, high throughput, and replayable streams. It’s foundational for event-driven architectures and ML feedback loops.
Apache Airflow
This workflow management tool is used to schedule complex data pipelines from ingestion to training. Airflow orchestrates complex workflows using Python-based DAGs. It handles scheduling, retries, dependencies, and lineage and is widely used for ETL, ML pipelines, and cross-system automation.
Apache Spark
This distributed compute engine for large-scale data processing supports SQL, machine learning, streaming, and graph analytics. It’s in-memory execution makes it significantly faster than traditional MapReduce.
dbt Core
This tool enables SQL-based data transformations with software-engineering best practices. It brings versioning, testing, documentation, and lineage to analytics pipelines. It’s ideal for building curated datasets and ML-ready tables.
Great Expectations
Great Expectations is a data quality and validation framework. It lets teams define ‘expectations’ for data and automatically test them. It generates human-readable reports and integrates seamlessly with pipelines.
JupyterLab
This is an interactive development environment for notebooks, code, and data exploration. It supports multiple kernels (Python, R, Julia) and rich visualisations. It’s the default workspace for data scientists.
Apache Superset
Superset is an open source BI and dashboarding platform. It offers SQL exploration, charting, and interactive dashboards. It’s lightweight, cloud-friendly, and ideal for analytics teams.
Jenkins
This widely used open source CI/CD automation server supports pipelines-as-code, plugins, and integrations with any tool. It’s often used to automate model packaging, testing, and deployment.
Docker
Docker packages ML code, dependencies, and models into portable containers. It ensures reproducibility across dev, test, and production. It’s essential for Kubernetes-based ML platforms.
Kubeflow Pipelines
This orchestrates end-to-end ML workflows on Kubernetes. It provides reusable components, metadata tracking, and experiment management, and is ideal for scalable, cloud-native ML training.
PyTorch/TensorFlow/scikit-learn
These are the core open source ML frameworks.
- scikit-learn: Classical ML, fast prototyping
- PyTorch: Flexible deep learning, research-friendly
- TensorFlow: Production-grade deep learning with strong ecosystem support
MLflow Model Registry
Model Registry stores, versions, and manages ML models. It supports lifecycle stages (staging → production), lineage, and approvals. It integrates with MLflow tracking and serving tools.
Seldon Core
Seldon Core deploys and serves ML models on Kubernetes. It supports REST/gRPC endpoints, canary releases, A/B tests, and explainers. It’s highly scalable and production ready.
Prometheus + Grafana
Used for monitoring, these visualise performance metrics and identify anomalies. Prometheus collects time-series metrics, and Grafana visualises them. Together, they provide observability for ML services (latency, throughput, errors).
ELK Stack (Elasticsearch, Logstash, Kibana)
The ELK stack handles centralised logging and search. Logstash ingests logs, Elasticsearch indexes them, and Kibana visualises them. ELK is widely used for debugging ML pipelines and services.
Kafka (Feedback Loop)
Kafka captures predictions, outcomes, and user interactions for retraining. It enables event-driven ML and continuous learning.
| MLOps framework steps | Tools used |
| Data ingestion | Apache NiFi, Airbyte, Slinger, Kafka |
| Orchestration | Apache Airflow, Kubeflow Pipelines |
| Data processing | Apache Spark, dbt Core, Great Expectations |
| Analytics and exploration | JupyterLab, Apache Superset |
| Model development | PyTorch, TensorFlow, Scikit-Learn |
| CI/CD and packaging | Jenkins, Docker |
| Model registry | MLflow Model Registry |
| Observability | Prometheus + Grafana, ELK Stack |
| Feedback loop | Kafka |
Table 2: Open source tools used in the different steps of the MLOps framework
LLMOps: The future of MLOps
Generative AI models have become mainstream in enterprise development. Organisations are now shifting toward LLMOps, or large language model operations, to manage autonomous agentic workflows and enforce safety and governance. LLMOps spans prompt management, vector-store orchestration, fine-tuning pipelines, predictive modelling, integrated safety layers, and continuous evaluation, enabling reliable, governed, and cost-efficient scaling of genAI systems. This evolution requires traditional MLOps teams to expand their skills and operate as LLMOps practitioners to ensure generative outputs remain secure, aligned, and trustworthy.
The core capabilities of LLMOps are:
Prompt management and versioning
Track, test, and optimise prompts as first-class artifacts.
RAG (retrieval-augmented generation) operations
Manage vector databases, embeddings, chunking strategies, and retrieval pipelines.
Model lifecycle management
Handle fine-tuning, model selection, model switching, and rollback.
Evaluation and benchmarking
Continuous testing for hallucinations, toxicity, bias, and factual accuracy.
Observability and monitoring
Track latency, cost, token usage, drift, and user feedback loops.
Safety, guardrails and policy enforcement
Apply content filters, grounding, red-teaming, and enterprise-grade safety layers.
Cost optimisation
Manage model routing, caching, batching, and hybrid model strategies.
Some of the open source LLMOps tools/frameworks are: LangChain/LangGraph, LlamaIndex, Haystack, Agenta, Langfuse, Chroma, Milvus/Weaviate, and Arize Phoenix.
MLOps has progressed from ‘model operations’ to ‘intelligence operations’, supporting AI systems that learn continuously, act autonomously, and operate safely at enterprise scale. CIOs need to treat MLOps as a core enterprise capability, not a data science accessory. MLOps tools and frameworks need to become the norm, especially for enterprises with sensitive data. They must invest in cross-skilling data engineers, ML engineers, and DevOps teams.
As generative AI models become mainstream, the future seems to be the emergence of LLMOps. However, managing LLMs introduces new challenges like prompt management, fine-tuning pipelines, vector stores, and safety layers. MLOps teams must evolve into LLMOps teams, integrating agentic workflows and safety governance.
Acknowledgements
The authors would like to thank Tricon Solutions LLC and Gspann Technologies, Inc., for giving the required time and support in many ways when this article was being written.
Disclaimer: The views expressed in this article are those of the authors. Tricon Solutions LLC and Gspann Technologies, Inc., do not subscribe to the substance, veracity or truthfulness of the said opinion.
















