






























































Faster than conventional databases, RethinkDB works in real-time. This open source, distributed and document-oriented database is designed to store JSON documents in an operable format with sharding and replication.
Traditional database management systems have similar structures and share common methods to insert, delete, update and query information. NoSQL based database systems, however, offer developers many choices for their specific data storage requirements. New scalability features have revolutionised these databases, though most NoSQL systems still rely on the creation of a specific structure that is organised collectively into a record of data. The access models of NoSQL based systems have not adapted to modern Web applications when it comes to fetching information, adding records to data and getting the information pulled out; rather, the user just queries the database by specifying some significant values.
RethinkDB takes an entirely novel approach to creating a database structure, as well as in the techniques it uses to store and retrieve information. RethinkDB works in real-time, and is an open source, distributed and document-oriented database designed to store JSON documents in an operable format with sharding and replication. It provides real-time pushing of JSON data to the server, which entirely redefines real-time Web application development. It implements a proprietary, function-based query language called ReQL to interact with its schemaless JSON data collections. Like MongoDB, documents in RethinkDB are hierarchical, dynamically typed and schemaless objects.
RethinkDB makes use of a custom-built storage engine primarily based on the Binary Tree File System (BTFRS) from Oracle, which promises various significant advantages such as less overhead on the CPU, SSD optimisation, power failure recovery, support for MVCC, and efficient multi-core operation and data consistency when failures occur.
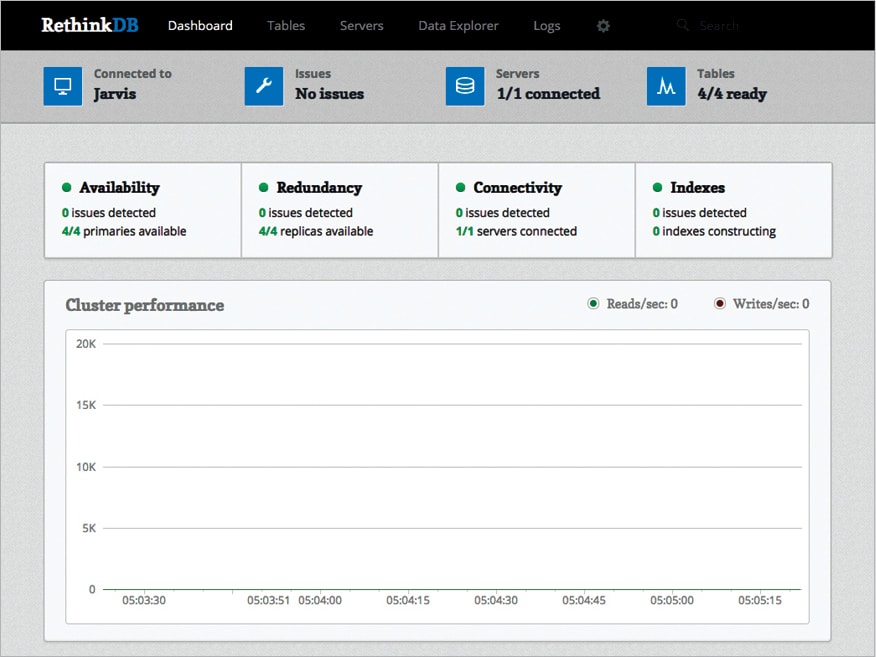
RethinkDB architecture
RethinkDB consists of different components like a cluster, query execution engine, file system storage, push changes and RethinkDB client drivers.
- Client drivers: RethinkDB provides client drivers for various popular programming languages like Ruby, Python, Java, etc.
- Query engine: This database has an advanced query handler to perform all sorts of query executions and give results back to the user. It performs queries on the basis of various operations like indexing, sorting, cluster searching and data merging.
- Clusters: As RethinkDB is a distributed database, the entire distribution is managed through clustering—sharding or replication.
- Push changes to the RethinkDB client: This is the most significant concept in RethinkDB. Rather than see the changes in the database through the polling approach, RethinkDB pushes the changes in old and new values to connected clients. The clients that are connected in real-time to the database server can see the live changes in the server.
- Query execution: RethinkDB is perhaps the best in performing various complex computations and internal logic operations. In order to handle queries, RethinkDB divides the queries into stacks. Every stack consists of various methodologies as well as internal logic to perform operations. In order to optimise the query response, the stacks are transported to the related server and every server performs the evaluation in parallel. Then queries are combined together to get the result set, which is sent back to the client.
In order to provide high performance and concurrency, RethinkDB makes use of multi-version concurrency control (MVCC). With this, every user can see a snapshot of the data, and if any changes happen in the master copy, child copies or snapshot copies are not updated until the master copy is committed.
The sharding process in RethinkDB
RethinkDB makes use of an advanced algorithm to perform sharding operations. Sharding is done on the primary key of the table for data partitioning and doesn’t make use of any other keys. In RethinkDB, the primary key and the shard key are the same.
The sharding process can take place in two ways.
- Vertical partitioning: Users store the data in different tables with different documents in varied databases.
- Horizontal partitioning: A dynamic algorithm (i.e., the Range Shard algorithm) is used to determine the break point of the table and store the data in different shards on the basis of calculations.
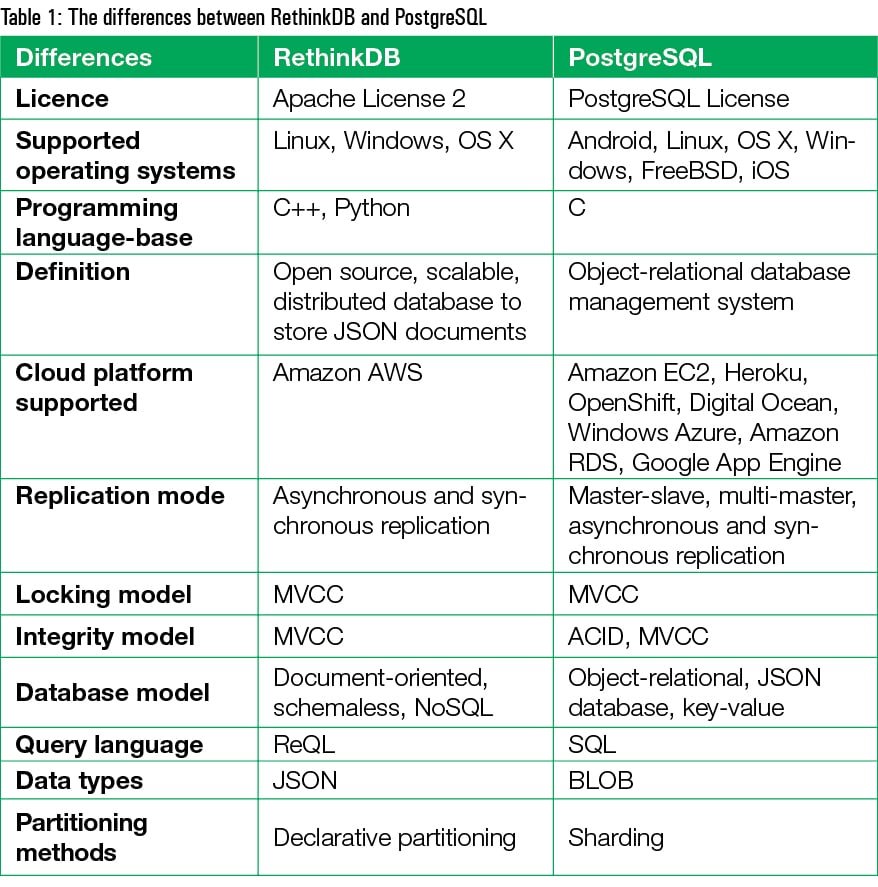 Features of RethinkDB
Features of RethinkDB
- Changefeeds: RethinkDB is a database designed especially for real-time applications. Using change feeds, developers can efficiently program the database to push the latest data feeds to applications in real-time. This ‘change feeds’ feature overcomes the limitations of polling as the database reduces the time and complexity when responding to user queries and can support Web apps in real-time.
- Scalability: RethinkDB provides users with high flexibility and improved storage. The processing power of the server can be expanded in real-time by adding more servers to the cluster.
- Powerful ReQL – a query language: ReQL is a data-driven, abstract and advanced language to build applications. It is designed to work as a full-fledged API to change and compose all sorts of queries. All queries sent to the server are parallelised automatically on the database server and split across multiple data centres.
- Developer friendly: RethinkDB is very developer friendly and combines easy language with simple controls. With RethinkDB, developers can build real-time applications due to faster interactions with user responses.
- Document-oriented structure: It is a document database built from scratch. Working on certain objects in a database may be quite cumbersome for developers as various issues like data mapping can arise. With RethinkDB, these issues are resolved by replacing the row concept with a more flexible model called a document, as documents are objects.
- Distributed joins: Most of the NoSQL databases don’t support joins, as the latter are not covered under the data model function but just as a function of data access. RethinkDB fully supports joins and automatically compiles them to distributed programs, executing them across clusters without any sort of manual intervention by the client.
An introduction to ReQL
ReQL (RethinkDB Query Language) is regarded as a powerful query language for performing all sorts of operations on JSON documents. Compared to other NoSQL query languages, ReQL provides powerful features and is built on the following three key principles.
- Embeds into the programming language: All the queries are developed by using function calls in programming languages. There is absolutely no requirement for concatenation of strings or construction of specialised JSON objects for the database query.
- All queries are chainable: A user can start with a table and increment chain transformers to the query end using the ‘.’ operator.
- Queries are executed on the server: Queries are made by the client on the respective machine, but once the user presses the Run command, the queries pass through the client machine to the server through the active network connection, and entire queries are executed on the database.
Features of ReQL
- Efficient: Like other database systems, ReQL supports all sorts of primary and secondary indexes for efficient access to data. Users can create compound indexes on the basis of arbitrary ReQL expressions in order to speed up the query process.
- Parallel query execution: Every user query is split across different cores of the CPU, server clusters or multiple data centres. RethinkDB and ReQL break the queries into stages and execute every stage in parallel; after completing the query, all data sets are combined to give the end result to the user.
- Query optimisation: ReQL is powerful enough as a query optimiser to maintain chains and alternative implementation plans to improve the overall performance of the database.
- Other features: ReQL builds queries of arbitrary complexity; there is no new type of syntax or command for executing complex queries, and it allows modular programming when creating sub-queries and for handling user responses.
Data types
The ReQL data types can be categorised as follows:
- Basic data types
- RethinkDB specific data types
- Abstract data types
- Geometry data types
Basic data types
- Number: Any real number like 89, 4.561, -76, etc
- Strings: Any valid UTF-8 string like ‘alphabet’
- Booleans: True/false
- Objects: JSON data objects
- Arrays: Elements of similar data types like [1 2 3], [red orange mango]
Specific data types
- Databases: RethinkDB databases
- Tables: RethinkDB database tables
- Streams: These list data types like arrays
- Selections: Subsets of tables
- Pseudo types: Different kinds of ReQL-specific data types which are generally composite, or special cases of other types like binary objects, times, geometry data types, grouped data
Abstract data types
- Datum: Used for most non-stream data types including basic data types, pseudo types, objects, and non-stream selections
- Sequences: These list data types like arrays, streams, selections and tables
- Functions: These are passed as parameters to various ReQL commands
Geometry data types
- Points
- Lines
- Polygons
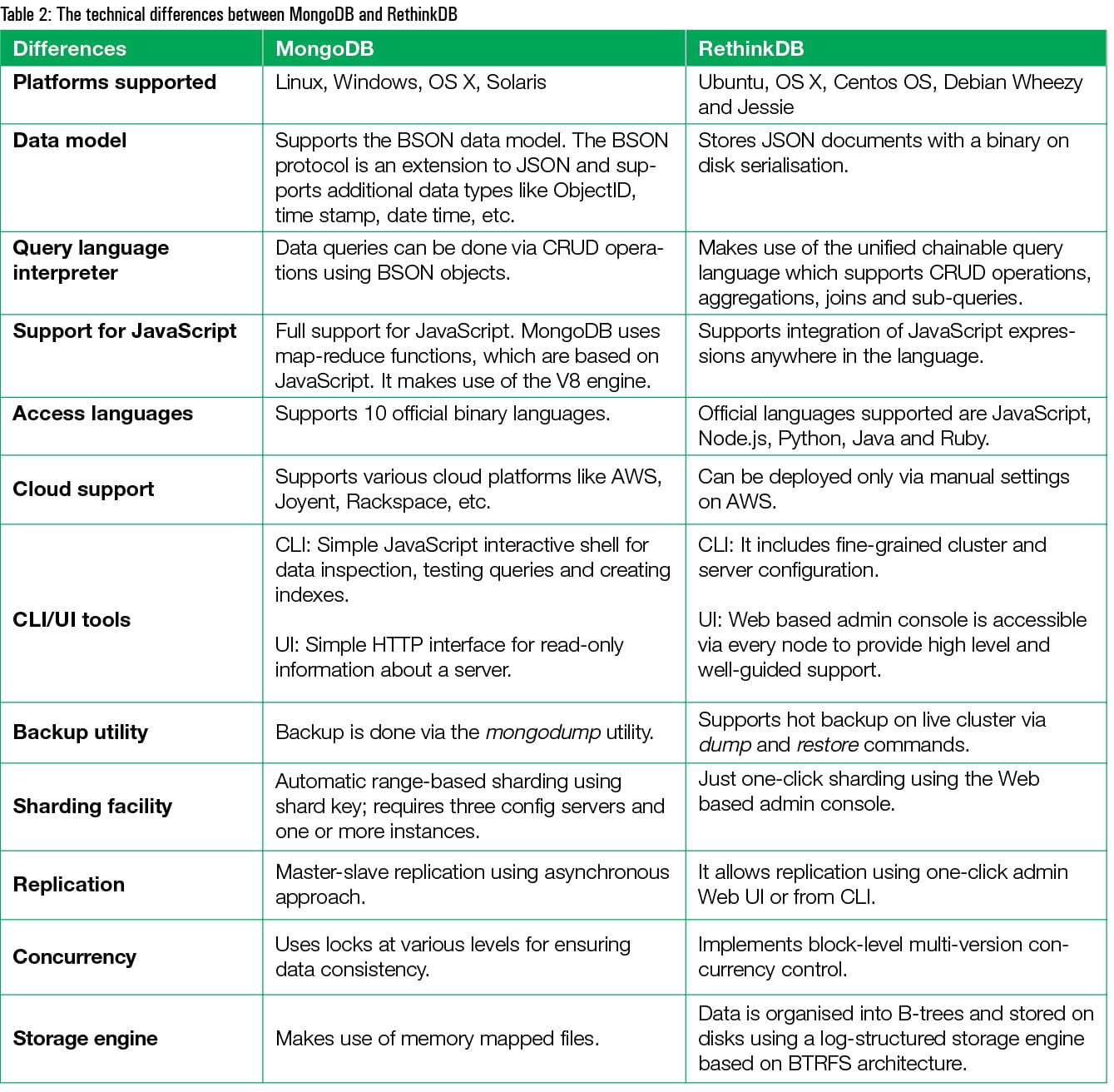 RethinkDB versus MongoDB
RethinkDB versus MongoDB
RethinkDB is considered as a good choice for those developers who build real-time applications. When a user makes a request, the application needs to respond at near-instantaneous speeds. Like MongoDB, RethinkDB is a fast and flexible JSON-based database management system.
RethinkDB is no doubt a good database engine but it has certain limitations in terms of administration and development. So when it comes to the overall rating of RethinkDB as compared to MongoDB, the latter is better on a few counts ( see Table 2).
















