






























































The term MLOps is coined from the words ‘machine learning’ and ‘operations’.
It is a practice for collaboration and communication between data scientists and operations professionals to help manage the production machine learning (or deep learning) life cycle. It is similar in concept, though not the same as DevOps.
Let’s delve into this emerging world of Machine Learning Ops (MLOps) to understand its various facets. Machine learning (ML) is all pervasive nowadays. If we look at the various categorisations of the ML investment spectrum, ML applications take the largest pie of $US 28 billion, whereas ML platforms follow with US$ 14 billion. These two comprise more than 80 per cent of the total investments. Spending on machine learning is estimated to reach US$ 57.6 billion dollars by 2021, at a compound annual growth rate (CAGR) of 50.1 per cent.
With this kind of proliferation, there is bound to be a plethora of tools available at our disposal to implement an end-to-end ML workflow. This is where the emerging trends of Machine Learning Ops (MLOps) come into play. MLOps has some similarities with DevOps, but one of the major differences between the two is that MLOps is about managing the deployment of ML models and pipelines, whereas DevOps is about the deployment of the code. In this article, we will investigate the taxonomy of a few MLOps tools.
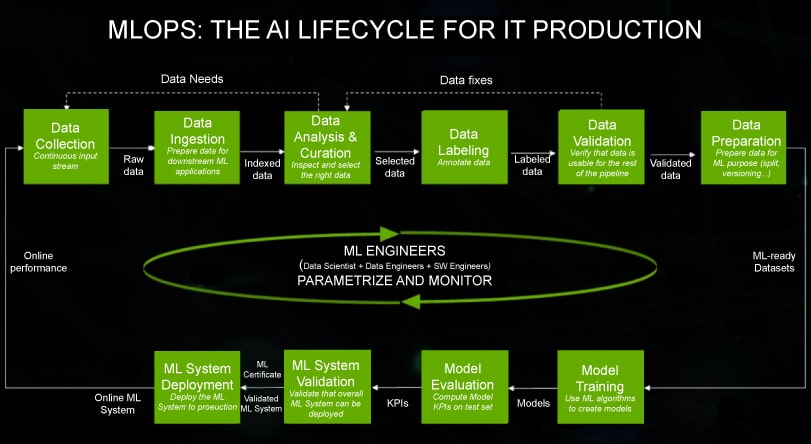
Let us look at the sample life cycle of MLOps, courtesy NVIDIA.
The overall idea of MLOps is simple yet intriguing. There are two ways to look at it — first, one can consider it as a connected flow of various data-centric operations to explore, manage, process and visualise the data to get the model out of it. This is shown in Figure 1. It shows a continuum of data extraction (data needs) with data marshalling (data fixes) to make it appropriate for ML modelling. The ML part of the workflow consists of the usual training, validation, testing and deployment. The loop continues with successive training to adopt the changes in data and hence the underlying model.
Second, MLOps is a layer sitting on top of the usual DevOps. Basically, it is a logical extension of DevOps. This is more relevant when one talks about a logical migration from existing DevOps to MLOps. Figure 2 depicts the same.

In a paper titled ‘Hidden Technical Debt in Machine Learning Systems’ written by a few distinguished Google ML practitioners, some pertinent questions have been raised. These are the fundamental questions that MLOps seeks an answer to. The basic idea is simple. How can one take a look at the technical debt acquired by an ML system? Traditionally, we have OOPS concepts like abstraction and encapsulation. But ML systems often, by their very nature, violate those boundaries based on various traits and prejudices. So, how does one measure the technical debt of an ML system? The paper discusses some of the relevant questions that are given below.
1. How easily can a new approach (design, algorithm and model) be retrofitted and tested?
2. How entangled are the data dependencies? For example, if I want to get rid of some input data stream, what all do I need to modify?
3. Can we measure the impact of a new change precisely?
4. How are the models integrated? Does a change in one cause others to degrade?
5. If a new person joins the team, how quickly can she/he adopt?
[Ref: https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf]
| Phase | Purpose | Tools |
| CI/CD for ML | The continuous integration/continuous delivery tool chain |
Continuous Machine Learning (CML) |
| Data exploration | Tools to perform the data exploration | Apache Zeppelin, Google Colab, Jupyter Notebook, JupyterLab, Jupytext, Polynote, etc |
| Data management | Tools for performing the data management phase | Arrikto, Data Vision Control(DVC), and Intake. |
| Data processing | Tools for data processing and pipelining | Airflow, Hadoop, and Spark |
| Data visualisation | Visualisers for the data | Dash, Data Studio, Metabase, Redash, Superset, Tableau, etc |
| Feature store | Feature store tool for data serving | Butterfree and Feast |
| Hyper parameter tuning |
Tools for the ML/DL model hyperparameter tuning |
Hyperas, Hyperopt, Katib, Optuna, Scikit Optimize, Tune, etc |
| Knowledge sharing | Tools for knowledge collaboration | Knowledge Repo, Kyso, etc |
| ML platforms | Complete ML platform | Algorithmia, Allegro AI, CNVRG, Cubonacci, DAGsHub, Dataiku, DataRobot, Domino, Gradient, H2O, Hopsworks, Iguazio, Knime, Kubeflow, LynxKite, ML Workspace, Modzy, Pachyderm, Polyaxon, Sagemaker, and Valohai |
| Model life cycle | Tools to manage the ML model life cycle | Comet, Mlflow, ModelDB, Neptune AI, Sacred, etc |
| Model serving | Tools for deploying and serving the production model |
BentoML, Cortex, GraphPipe, KFServing, PredictionIO, Seldon, Streamlit, TensorFlow Serving, TorchServe |
| Model optimisation | To manage model scalability | Dask, DeepSpeed, Fiber, Horovod, Mahout, MLlib, Modin, Petastorm, Rapids, Ray, Singa, Tpot, etc |
| Simplification tools | Tools related to ML simplification and standardisation |
Hermione, Koalas, Ludwig, PyCaret, and Turi Create |
| Workflow tools | Tools pertaining to create ML pipelines | Argo, Flyte, Kale, Kedro, Luigi, Metaflow, Prefect, etc |
Table 1: Taxonomy of the MLOps tools [Ref: https://github.com/kelvins/awesome-mlops]
Taxonomy
We have described the basic idea of MLOps above. We can categorise the various tools available to us based on the taxonomy given in Table 1 above.
To conclude, MLOps is the efficient and holistic management of ML pipelines and models from an end-to-end perspective, whereas DevOps talks about the management of code and bringing development closer to the operation. This article discussed some of the challenges related to ML technical debt management, and then presented a comprehensive taxonomy of tools across the whole spectrum of MLOps. Of course, as this is an emerging field, tools are being added every other day.


















