

Our world is currently dominated by automation. Instant help from chatbots, email filters, voice assistants, predictive text, and search results are all examples of artificial intelligence (AI) and one of its primary branches, natural language processing (NLP). In this article we take a look at how these technologies use neural networks.
Neurons in the human brain are interconnected to help make a judgement call; neural networks are inspired by these neurons and assist a computer to make distinct decisions or predictions. Neural networks are made up of a web of interconnected nodes, each of which is responsible for performing simple calculations to achieve the desired outcomes. Some of the important neural networks are:
- Recurrent neural networks (RNN)
- Artificial neural networks (ANN)
- Convolutional neural networks (CNN)
Recurrent neural networks
Recurrent neural network (RNN) is a powerful deep learning technology that is crucial to understand if you want to get into machine learning. We are all probably indirectly using RNN based applications in our smartphones and websites. Speech recognition, language translation, and stock predictions all use RNNs. These neural networks excel at modelling sequence data.
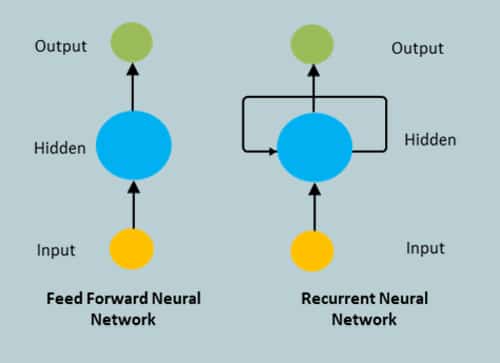
The information in a feed-forward neural network flows only in one way — from the input layer to the output layer, passing through the hidden layers. Feed-forward neural networks have no recollection of the information they receive and are bad at predicting what’s coming next. A feed-forward network has no concept of time order because it only analyses the current input. It has no recollection of what happened in the past, apart from its training. An RNN’s information is cycled in a loop. It considers the current input as well as what it has learned from previous inputs before making a decision. Recurrent neural networks, to put it simply, blend information from the past with information from the present. This signifies that the output will be sent back to the input and then used when the next input comes along, in the next time step. Essentially, the network’s ‘state’ is propagated forward in time. RNNs are neural networks that travel across time.
Figure 2 illustrates the difference in information flow between a feed-forward neural network and RNN.
In the feed-forward neural networks, all test cases are considered to be independent. Take an example of sequential data, which can be the flight booking data for an airline company. A simple machine learning model or an artificial neural network may learn to predict ticket demands based on several features — source-destination, schedule-time (morning, midnight), etc. While the demand for tickets depends on these features, it is also largely dependent on the ticket demand in the previous days or weeks, or months. In fact for a trader, these values in the previous days (or the trend) are one major deciding factor for sales predictions. Recurrent neural networks are used to achieve this time dependency. A typical RNN is shown in Figure 3.
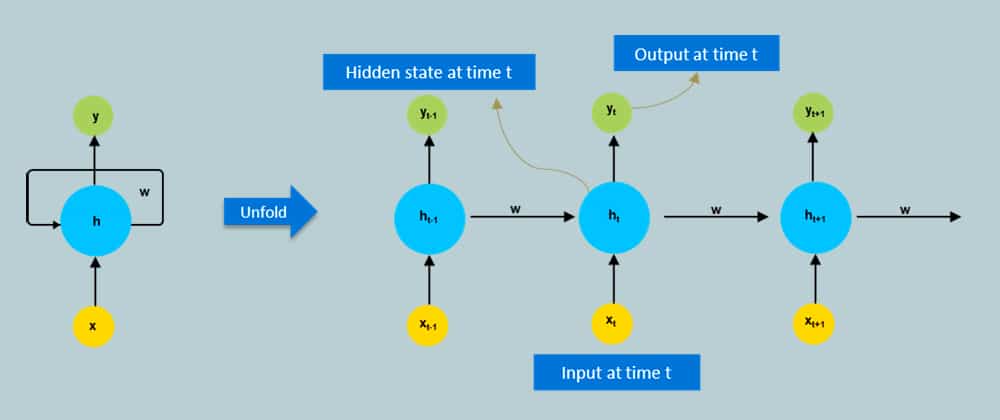
RNNs are widely utilised in natural language processing. They have sharing features learned across multiple text positions, which is not the case with a normal neural network. Traditional neural networks are unable to predict future inputs based on previous ones.
LSTM (long short-term memory): An improvement over RNN
RNNs are wonderful for short contexts, but we need our models to be able to grasp and recall the context behind the sequences, just like a human brain, to form a collection and remember it. With a simple RNN, this is not achievable. For example, in the sentence ‘The lemon tastes _______.’ RNNs turn out to be quite effective. This is because this problem has nothing to do with the context of the statement. The RNN need not remember what was said before this, or what its meaning was. All it needs to know is that in most cases the lemon is sour. Thus the prediction would be: ‘The lemon tastes sour.’
Another example is, ‘I spent many years in my early career in Japan. Then I came back to my motherland. ….. I can speak fluent __?__. We can understand that since the author has worked in Japan for many years, it is very likely that he may possess a good command of Japanese. However, to produce an accurate forecast, the RNN must remember the context. A RNN fails in this situation! The problem of ‘vanishing gradient’ is the explanation for this. A large amount of unnecessary data may separate the relevant information from the point where it is required. To understand this, you must first understand how a feed-forward neural network learns. We know that in a conventional feed-forward neural network, the weight updation applied to a specific layer is a multiple of the learning rate, the error term from the previous layer, and the input to that layer. RNN remembers things for just a small period, i.e., if we just need the information for a short period, it may be replicable, but once a large number of words are entered, the information is gone. LSTM (long short-term memory) is a unique kind of RNN that has the capability of learning lengthy-time period dependencies. It tends to remember facts for long periods of time as their default behaviour.
LSTM units (or blocks) serve as a foundation for RNNs. An LSTM network is an RNN that is made up of LSTM units. A cell, an input gate, an output gate, and a forget gate make up a typical LSTM unit. The LSTM term ‘memory’ refers to the cell’s responsibility for ‘remembering’ values over arbitrary time intervals. Each of the three gates can be called a ‘traditional’ artificial neuron in a multi-layer (or feed-forward) neural network; they compute the activation of a weighted sum (using an activation function). They can be considered as regulators of the flow of values that pass through the LSTM’s connections, hence the name ‘gate’. Between these gates and the cell, there exist connections.
We can understand why LSTM is preferable over RNN in the context of natural language processing and suggesting text auto-complete across longer sentences. The impact of the word early in the sentence can determine the meaning and semantics of the end of the sentence. Unlike RNN, the LSTM architecture introduces ‘cell states’, which can bring meaning from the beginning of the sentence to the end of the sentence. What’s fascinating is that it can also be bidirectional, so the later words can provide context to the early words. Based on what word appeared at the beginning, your auto complete sentence might be different. In the example given in Figure 4, the first word in the second sentence differs based on the very first word (far away from the second sentence).

Most state-of-the-art NLP models were based on RNN before the release of the transformer. RNN accesses the cell of the final word by processing data word by word. Long sequences are difficult for RNN to handle. The model tends to forget distant position contents or, in some situations, to mix neighbouring position contents. The more steps, the more difficult it is for the recurrent network to make decisions.
LSTM outperforms traditional RNNs by a small margin. The gate mechanism is used by LSTM to determine which information the cell should remember and which it should discard. It can also solve the problem of disappearing gradients that RNN has. LSTM is adequate, but not sufficient. LSTM, like the RNN, cannot be trained in parallel. If we simplify how LSTMs function, we can say that the process is broken down into multiple steps. To begin with, LSTMs forget irrelevant information about the current state of the cell. Then they update it with new information before calculating the result.
Convolutional neural networks (CNNs) have an advantage over RNNs (and LSTMs) as they are easy to parallelise. CNNs are widely used in NLP because they are easy to train and work well with shorter texts. They capture interdependence among all the possible combinations of words. However, in long sentences, capturing the dependencies among different combinations of words can be cumbersome and unpractical.
Transformers in NLP
For decades, AI researchers have drawn their inspiration from the human brain. One of AI’s most elusive ambitions is to recreate the brain’s cognitive skills in deep neural networks. Attention is one of those mysterious human brain skills that we don’t fully comprehend. What brain mechanisms enable us to concentrate on a single task while ignoring the rest of our surroundings? In deep learning models, attention mechanisms have recently become a source of inspiration.
A transformer, one of the biggest breakthroughs in NLP, is a deep learning model that uses the attention mechanism to weigh the importance of each element of the input data differently. The transformer model in NLP has fundamentally altered how we work with text data. The paper ‘Attention Is All You Need’ published in 2017, describes transformers and what is called a sequence-to-sequence architecture. Transformer is a special type of sequence-to-sequence model used for language modelling, machine translation, picture captioning and text generation. Sequence-to-Sequence (or Seq2Seq) is a neural network that converts one sequence of components into another, such as the words in a phrase. Transformers, unlike RNNs, do not always process data in the same order. The attention mechanism, on the other hand, provides context for any point in the input sequence. For example, if the input data is a natural language sentence, the transformer does not need to process the first half of the sentence before proceeding to the final. Rather, it detects the context that gives each word in the phrase its meaning. Because this feature enables higher parallelisation than RNNs, training times are reduced.
The LSTM modules can offer meaning to the sequence while remembering (or forgetting) the parts they find significant (or unimportant) with sequence-dependent data. Sentences, for example, are sequence-dependent because the order of the words is critical for comprehension. For this type of data, LSTMs are an obvious choice. An encoder and a decoder are used in Seq2Seq models. The encoder is responsible for converting the input sequence into a higher dimensional space (n-dimensional vector). The abstract vector is passed through the decoder, which converts it into a series of outputs. The output sequence could be in a different language, symbols, a duplicate of the input, or something entirely different.
Transformer, like LSTM, is architecture for converting one sequence into another using two parts (encoder and decoder). However, it differs from the previously described/existing sequence-to-sequence models in that it does not employ recurrent networks (GRU, LSTM, etc). Transformers have replaced RNN models like LSTM as the preferred model for NLP challenges. Training on larger data sets is now possible thanks to the extra training parallelisation. As a result, pre-trained systems like BERT (bidirectional encoder representations from transformers) and GPT (generative pretrained transformer) have emerged, which were trained on big linguistic data sets like the Wikipedia Corpus.
Transformers essentially combine self-attention concepts. They do exceptionally well in machine translation jobs. How do they manage to do this? A bunch of encoders and decoders are placed on top of one another. This architecture was first proposed in a work that used six encoders and six decoders. Other numbers can also be used. Each encoder has two components — the self-attention layer and the feed forward neural network, while each decoder has three components — the self-attention layer, the decoder attention layer, and the feed forward neural network. A list of input vectors is sent to the first encoder. This is frequently an output of some kind of embedding layer when we work with words. It uses a self-attention layer and subsequently a feed-forward neural network to handle them. Following that, it passes the output to the next encoder. The information is sent to the decoders by the final encoder, who performs a similar process.
Working with Hugging Face
Hugging Face, which began as a chat app for bored teenagers, now provides open source NLP tools and has rapidly developed language processing skills. The company’s goal is to develop NLP and make it more accessible to all. Hugging Face has emerged as one of the biggest AI communities in NLP open source. It has established a comprehensive library with diverse resources in order to democratise NLP and make models available to everyone. Data sets, tokenisers and transformers are just a few of the tools available to help with NLP activities, which range from chatbots to question and answer systems.
The rapid growth of transformers has ushered in a new era of strong natural language processing technologies. Because these models are huge and expensive to train, academics and practitioners share and use pretrained versions. Hugging Face provides open source libraries with a variety of pretrained transformers that you can use with just a few lines of code. The app used to just support PyTorch, but now it also supports TF 2.0. The library has three sub-libraries.
- Transformers library
- Data sets library
- Tokenisers library
How to use Hugging Face transformer libraries
Installation: The transformers library is tested on Python 3.6+, and PyTorch 1.1.0+ or TensorFlow 2.0+. You first need to install one of these, or both TensorFlow 2.0 and PyTorch. When TensorFlow 2.0 and/or PyTorch have been installed, transformer installation can be done using pip, as follows:
!pip install transformers
Pipelines: The pipelines are an incredible and simple approach to utilise models for interfaces. These pipelines are objects that abstract the majority of the library’s sophisticated functionality, providing a straightforward API for a variety of tasks such as named entity recognition, masked language modelling, sentiment analysis, feature extraction, and question answering.
from transformers import pipeline
Sentiment analysis: Is a text positive or negative? This is an out-of-box API provided in transformer libraries.
from transformers import pipeline
sentiment = pipeline(‘sentiment-analysis’)
result = sentiment(‘The food was good. Will have to try again’)
print(result)
result = sentiment(‘The shirt I bought is nice, but it seems to be expensive’)
print(result)
The Output is:
[{‘label’: ‘POSITIVE’, ‘score’: 0.9995126724243164}]
[{‘label’: ‘NEGATIVE’, ‘score’: 0.9585908651351929}
Named entity recognition (NER): This deals with extracting entities from a given sentence.
ner = pipeline(‘ner’)
result = ner(‘Kolkata is known to be the one of the great city in India.’)
print(result)
The output is:
[{‘word’: ‘Kolkata’, ‘score’: 0.9992743730545044, ‘entity’: ‘I-LOC’, ‘index’: 1, ‘start’: 0, ‘end’: 7}, {‘word’: ‘India’, ‘score’: 0.992446780204773, ‘entity’: ‘I-LOC’, ‘index’: 13, ‘start’: 51, ‘end’: 56}]
Text summarisation: Summarisation takes in a passage as input and tries to summarise it.
summarizer = pipeline(“summarization”) my_text=”””On this day in 2011, India won the World Cup on home soil to send the entire country into euphoria. India had previously lifted the prized trophy in 1983 and had to wait a long time before doing it again. Led by MS Dhoni, India registered their second ODI title triumph by beating Sri Lanka in the final at the Wankhede Stadium in Mumbai on April 2, 2011. That day will be remembered for many a magical moments -- Gautam Gambhir’s brilliant knock, Dhoni’s iconic six, Sachin Tendulkar being carried around the ground by his teammates, to name a few.””” summarizer = pipeline(“summarization”) summarized_10 = summarizer(my_text, min_length=5, max_length=10) summarized_20= summarizer(my_text, min_length=5, max_length=20) summarized_40= summarizer(my_text, min_length=5, max_length=40) print(summarized_10) print(summarized_20) print(summarized_40)
The output is:
[{‘summary_text’: ‘ India won the World Cup on home’}]
[{‘summary_text’: ‘ India beat Sri Lanka in the 2011 World Cup final at the Wankhede Stadium’}]
[{‘summary_text’: “ India beat Sri Lanka in the 2011 World Cup final at the Wankhede Stadium in Mumbai . MS Dhoni’s iconic six and Gautam Gambhir’s brilliant knock were”}]
Translation from English to French: Let’s try and do a bit of translation, from English to French.
en_to_fr = pipeline(“translation_en_to_fr”, model=”Helsinki-NLP/opus-mt-en-fr”) en_to_fr(“Do you like reading story books?”)
The output is:
[{‘translation_text’: “Vous aimez lire des livres d’histoires ?”}]
NLP will become even more popular in the coming years as a result of ready-to-use pretrained models and low-code, no-code technologies that are available to everyone.
Businesses, in particular, will continue to gain from NLP, which will enable them to improve their operations, cut expenses, make smarter choices, and enable better customer experiences. Almost every communication we have with machines involves human communication, both spoken and written. NLP takes advantage of a deeper contextual understanding of the human language.



{kind=link}