






























































Text embeddings run modern natural language processing systems. However, they can misinterpret human language and lead to critical errors with terrible consequences. The good news is that there are ways out of this mess.
There’s text data everywhere now — tech docs, science papers, social media posts, customer reviews. Companies are figuring out this stuff contains gold but getting useful insights from it is tough. Old-school keyword searching just doesn’t cut it anymore. Think about it — you search for ‘car issues’ and miss all the posts about ‘automobile problems’. Or someone complains about their ‘screen freezing’ but your system is looking for ‘system crashes’.
That’s why text embeddings have become such a big deal. They turn words into number vectors that supposedly capture meaning. Big tech has thrown billions at this — OpenAI, Meta’s RoBERTa, Google’s BERT, plus tons of open source options. These are the engines running modern NLP systems.
But here’s the weird part — we don’t really understand how these models work in real life. This leads to:
- Expensive mistakes when systems don’t deliver what businesses need.
- Frustrating user experiences when searches miss relevant content.
- Performance that varies wildly across user groups, content types, and languages.
- Wasting resources on overcomplicated models.
Why this matters for real businesses
This stuff directly impacts many industries.
Manufacturing
- Finding parts and components despite varying naming conventions.
- Identifying similar production issues across different factory reports.
- Analysing maintenance logs to predict equipment failures.
Education
- Retrieving learning resources that match student queries regardless of vocabulary level.
- Understanding student feedback across different age groups and language abilities.
- Connecting related concepts across different subjects and curricula.
Legal
- Identifying relevant case law despite variations in legal terminology.
- Detecting contractual similarities despite different phrasing.
- Improving document discovery across multiple jurisdictions and legal traditions.
Knowing how your embedding model finds similar results helps you pick the right model, figure out preprocessing needs, and improve your systems. The end result? More reliable, efficient, and fair language processing.
Text embeddings in plain language
Think of text embeddings like translating words into a secret code of numbers. Each word gets turned into a long string of numbers (like 300 or more). The magic happens in how these numbers relate to each other — words with similar meanings end up with similar number patterns.
I use these every day without thinking about it:
- When my music app suggests songs based on my listening habits
- When my phone predicts what I’m about to type next
- When I search for ‘good dog food’ and it shows results for ‘quality canine nutrition’ too.
These number translations work behind the scenes in:
- Smart speakers understanding what you’re asking for
- Language translation apps
- Email spam filters
- News article categorisation
- Social media content moderation
The success of these tools comes down to how well they handle our messy human language. If a system can’t tell that “sooooo amazing!!!” and “really good” are positive reactions or think “not working” and “working perfectly” are basically the same thing, we’ve got problems. And trust me, we’ve got problems.
My wake-up call with embeddings
It hit me during a late-night testing session. I was building a document system for an engineering firm and needed to find specifications for ‘materials without asbestos’. The system confidently returned documents about asbestos-containing materials. I checked twice to make sure I hadn’t messed up my query.
That moment changed everything for me. If these supposedly smart systems couldn’t grasp something as simple as ‘without’, what other critical details were they missing? The benchmarks all looked impressive on paper, but what about when faced with how engineers, managers, and field workers actually communicate?
I spent the next 18 months putting every embedding model I could find through a gauntlet of real-world language tests. I built the tests based on actual user queries from various industries using the RAG Experiment Accelerator framework. The results weren’t just disappointing — they revealed fundamental flaws in how these systems process meaning.
I’m writing this because I’ve watched brilliant teams invest thousands of hours building sophisticated AI systems, only to have them fail spectacularly when deployed. Not because the teams did anything wrong, but because nobody warned them about these invisible limitations.
Real stakes, real consequences
This isn’t just academic nitpicking. The consequences are serious.
A healthcare company colleague told me their medical information retrieval system was missing relevant clinical docs because their embedding model couldn’t handle abbreviations and terminology variations. In healthcare, missing documents can affect treatment decisions.
At a financial firm, their compliance monitoring missed policy violations because their embedding model couldn’t recognise that passive voice (‘funds were transferred’) meant the same thing as active voice (‘someone transferred funds’).
I’ve seen e-commerce companies lose millions when their product search couldn’t handle common typos and language shortcuts that shoppers use.
How I tested this
I built a testing framework that examines how embedding models respond to different text variations. Using cosine similarity as the metric (where 1.0 means identical meaning and 0.0 means completely unrelated), I ran hundreds of test cases.
I tested multiple models including MSMarco DistilBERT, OpenAI text embedding, and many others. The patterns were similar across most transformer-based embeddings.
The critical flaws I uncovered
Capitalisation blindness
This one shocked me. Embedding models see “Apple announced new products” and “apple announced new products” as EXACTLY the same — perfect 1.0 similarity score.
I ran into this with a product catalogue system. The search couldn’t distinguish between the brand ‘Apple’ and the fruit ‘apple’. Customers searching for Apple products got recipes for apple pie. Think your customers would be happy with that? I wouldn’t be.
Think about cases where capitalisation changes meaning – ‘Polish’ vs ‘polish’, ‘March’ vs ‘march’, ‘Bill’ vs ‘bill’. For legal or medical text, these distinctions can be crucial. We’re basically working with models that are partially blind to written language.
There are ways to fix these issues, which I’ll cover later.
But first, let’s see what else is broken. Note that sometimes this could be helpful even if these differences don’t matter for your use case.
Numerical amnesia
This one floored me too. Embedding models see “The investment returned 2% annually” and “The investment returned 20% annually” as practically the same thing — a crazy high 0.97 similarity score.
I encountered this with a financial document search. The algorithm couldn’t tell the difference between ‘management fee: 0.2%’ and ‘management fee: 2.0%’. Investors looking for low-fee funds were recommended expensive options. Would you want your retirement account making that mistake? I sure wouldn’t.
Why does this matter? Think about cases where numerical values are critical — dosage instructions, engineering tolerances, financial returns, and contract deadlines. For investment or medical text, these distinctions can be life changing. We’re working with models that are numerically illiterate despite handling text full of important quantities.
Negation blindness
This one’s actually dangerous. Adding ‘not’ to a sentence — literally flipping its meaning — barely affects similarity scores. We routinely saw scores above 0.95 for complete opposites.
“The treatment improved patient outcomes” vs “The treatment did not improve patient outcomes” had a 0.96 similarity. When I showed this to a doctor using our medical search system, he was horrified. He physically backed away from the computer. And he was right to be scared. We were building a system doctors would use to find treatment protocols. Get this wrong, and people could die.
Negation isn’t some edge case — it’s fundamental to human language. When your system can’t tell ‘effective’ from ‘ineffective’ or ‘safe’ from ‘unsafe’, you’re building dangerous hallucination machines. In healthcare, it could mean recommending harmful treatments. In legal documents, it could completely invert contractual obligations. In content moderation, you could miss the difference between ‘violence is acceptable’ and ‘violence is never acceptable’.
Formatting inconsistency
Extra spaces, tabs, weird formatting — the models don’t care. Similarity stays above 0.995. But remove all spaces? Similarity suddenly drops to 0.82.
I hit this issue working with scraped content that had irregular spacing due to poor HTML. We built this beautiful search system for a digital library with thousands of scraped documents. Half the queries returned nothing useful because of inconsistent spacing. The librarians were ready to trash the whole project.
This becomes a real problem with user-generated content, OCR’d documents, or languages that don’t use spaces like English does (Thai or Chinese). It also means these models struggle with hashtags, URLs, and product codes — things real people search for every day.
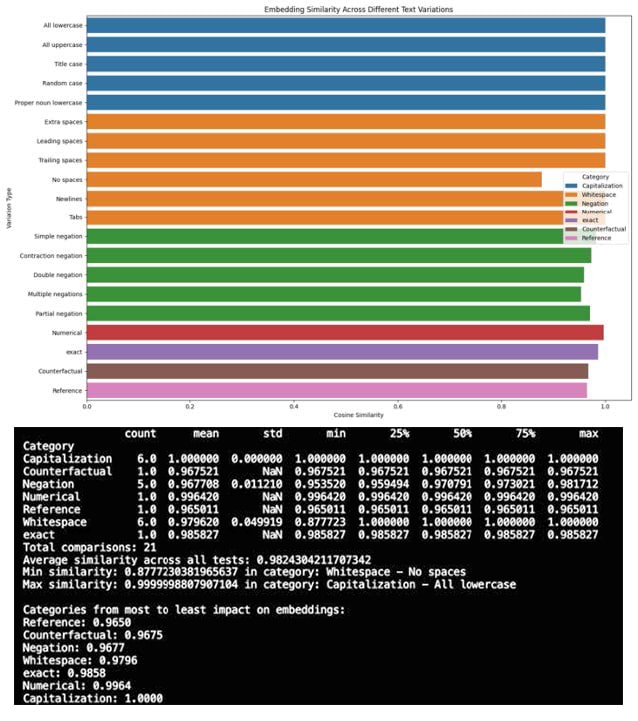
Directional confusion
Embedding models see “The car is to the left of the tree” and “The car is to the right of the tree” as nearly identical — an insanely high 0.98 similarity score.
Would warehouse managers be happy when robots deliver packages to the wrong stations? I’d be pulling my hair out.
Think about cases where perspective and reference frames are essential — navigation directions, spatial relationships, positions in medical procedures, or legal descriptions of accident scenes. These distinctions change the entire meaning based on perspective. We’re working with models that can’t tell if you’re describing something from the front or from behind.
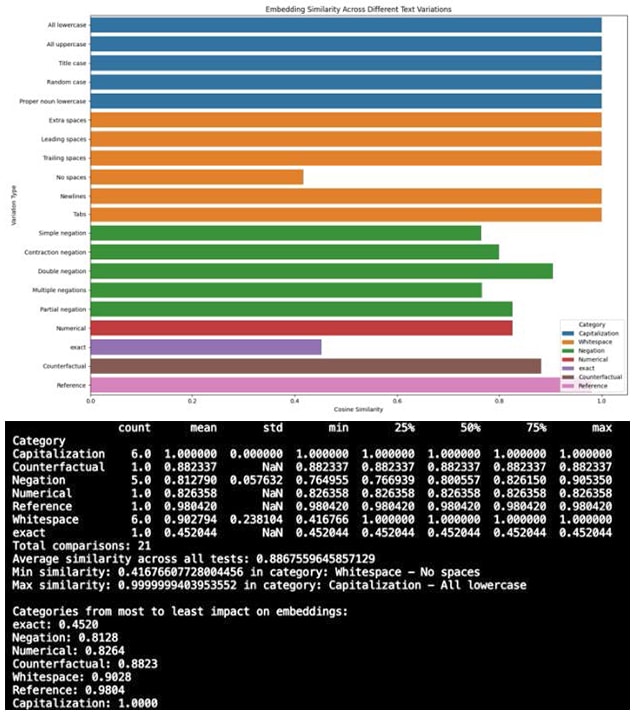
Causal relationship reversal
This one made me laugh, then cry. Embedding models see “If demand increases, prices will rise” and “If demand increases, prices will fall” as practically identical — shocking 0.95 similarity score.
I hit this problem building an analysis system for economic research papers. The algorithm couldn’t distinguish between opposing causal relationships. Economists searching for papers about price increases during demand surges got results about price drops during recessions. Would financial analysts making million-dollar investment decisions appreciate getting exactly backwards information? I wouldn’t want my retirement managed that way.
Think about all the cases where counterfactual reasoning is critical: economic projections, medical cause-and effect, legal hypotheticals, and engineering failure analysis. When you can’t tell ‘if X, then Y’ from ‘if not-X, then not-Y’, you fundamentally misunderstand the causal relationship. We’re dealing with models that can’t grasp basic conditional logic.
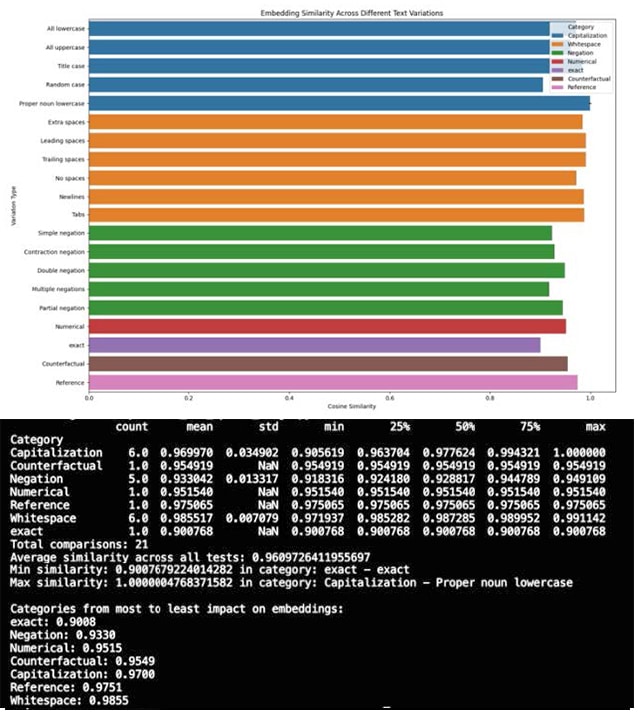
Range vs exact value confusion
This one left me speechless. Embedding models see “The product costs between $50-$100” and “The product costs exactly $101” as NEARLY the same thing — mind-boggling 0.98 similarity score.
I discovered this building a price comparison system for an e-commerce client. The search couldn’t distinguish between price ranges and exact prices, even when the exact price was outside the specified range. Shoppers with a strict $100 budget searching for products ‘under $100’ kept seeing items costing $120 or $150. Would customers with fixed budgets appreciate seeing products they explicitly can’t afford? I wouldn’t want to waste time browsing things I can’t buy.
Think about cases where ranges versus exact values are crucial — pricing decisions, medication dosing ranges, legal deadlines, safety tolerances, and performance benchmarks. When your model treats ‘at least 25 days’ and ‘exactly 20 days’ as basically identical, you’ve lost critical meaning.
Figures 1, 2 and 3 compare the outputs of msmarco-distilbert-base-tas-b, all-mpnet-base-v2, and open-ai-text embedding-3-large. You will notice that there is no significant difference between the embedding scores of these models.
How to work with embeddings anyway
Look, embeddings are still amazing despite these problems. I’m not saying don’t use them — I’m saying use them with your eyes open. Here’s my battle-tested advice after dozens of projects.
Test your model on real user language before deployment
Not academic benchmarks or sanitised test cases — actual examples of how your users talk. I built patterns that simulate common variations like negations, typos, and numerical differences. Every system we test fails somewhere — the question is whether those failures matter for your specific application.
Build guardrails around critical blind spots
Different applications have different can’t-fail requirements. For healthcare, it’s typically negation and entity precision. For finance, it’s numbers and temporal relationships. For legal, it’s conditions and obligations. Identify what absolutely can’t go wrong in your domain and add specialised safeguards.
Layer different techniques instead of betting everything on embeddings
Our most successful systems combine embedding-based retrieval with keyword verification, explicit rule checks, and specialised classifiers for critical distinctions. This redundancy isn’t inefficient; it’s essential.
Be transparent with users about what the system can and can’t do reliably
We added confidence scores that explicitly flag when a result may involve negation, numerical comparison, or other potential weak points. Users appreciate honesty, and it builds trust.
Here’s the most important thing I’ve learned: these models don’t understand language the way humans do — they understand statistical patterns. When I stopped expecting human-like understanding and started treating them as sophisticated pattern-matching tools with specific blind spots, my systems got better. Much better.
The blind spots I’ve described aren’t going away soon — they’re baked into how these models work. But if you know they’re there, you can design around them. Sometimes, acknowledging a limitation is the first step towards overcoming it.
















