

Offline intelligence is no longer an exception. It is an emerging foundation for the next generation of AI systems. Learn how we can build a secure and transparent locally hosted private assistant.
Artificial intelligence today is largely powered by the cloud. From chatbots and virtual assistants to content generation tools, most AI-driven experiences depend on remote servers owned and operated by a small group of technology providers. While this approach has enabled rapid adoption and scalability, it has also raised persistent concerns around data privacy, latency, cost, and dependence on third-party platforms. As AI systems increasingly handle personal, professional, and even sensitive information, these concerns can no longer be ignored.
This has led to renewed interest in the idea of sovereign AI, where intelligence is built and operated under the user’s direct control. Sovereign AI emphasises local execution, ensuring that data never leaves the device or organisational boundary. Until recently, running advanced language models locally was considered impractical due to their computational demands. However, improvements in hardware acceleration and model optimisation have made it possible to run capable large language models on personal machines.
Open source large language models (LLMs) have been central to this shift. Models that once required large-scale infrastructure can now be deployed locally with careful configuration. Advances in inference engines, quantization techniques, and GPU utilisation have significantly reduced resource requirements while maintaining useful performance. This has made AI development more accessible, allowing individuals and small teams to experiment without relying on paid APIs or constant internet connectivity.
One of the most compelling outcomes of this movement is the ability to build a private AI assistant. A locally hosted assistant can operate offline, interact securely with private files, and be tailored to specific workflows. More importantly, it offers transparency and predictability, shaped entirely by system prompts and configurations defined by its creator. We will explore how to build such an assistant step by step, demonstrating that offline, private intelligence is not a future concept but a practical reality available today.
Hardware requirements and optimisation
Running a large language model locally shifts the responsibility of computation from the cloud to the user’s machine. As a result, hardware selection plays a crucial role in determining both performance and usability. Unlike cloud platforms that abstract infrastructure concerns, local deployment requires a practical understanding of how CPUs, GPUs, memory, and storage interact during model inference. The good news is that modern consumer hardware is far more capable than it appears, provided it is used efficiently.
For many entry-level setups, the central processing unit serves as the starting point. Contemporary multi-core CPUs can run smaller language models reasonably well, especially when paired with optimised inference engines. While CPU-based inference may not match the responsiveness of GPU-backed systems, it remains a viable option for experimentation, learning, and lightweight assistants. This makes local AI accessible even on machines without dedicated graphics hardware.
Graphics processing units significantly enhance the experience of running local LLMs. GPUs accelerate matrix operations that are fundamental to deep learning inference, resulting in faster response times and smoother interactions. Video memory becomes a key consideration here, as larger models require more VRAM to load efficiently. Techniques such as model quantization allow these models to consume less memory, enabling them to run on mid-range consumer GPUs without compromising usability.
Beyond compute hardware, system memory and storage also influence performance. Adequate RAM ensures that models load smoothly and prevents bottlenecks during execution, while fast solid-state storage reduces initialisation time. Equally important is thermal management, as sustained inference workloads can push hardware to its limits. With thoughtful optimisation and realistic expectations, even modest systems can serve as capable platforms for private AI assistants.
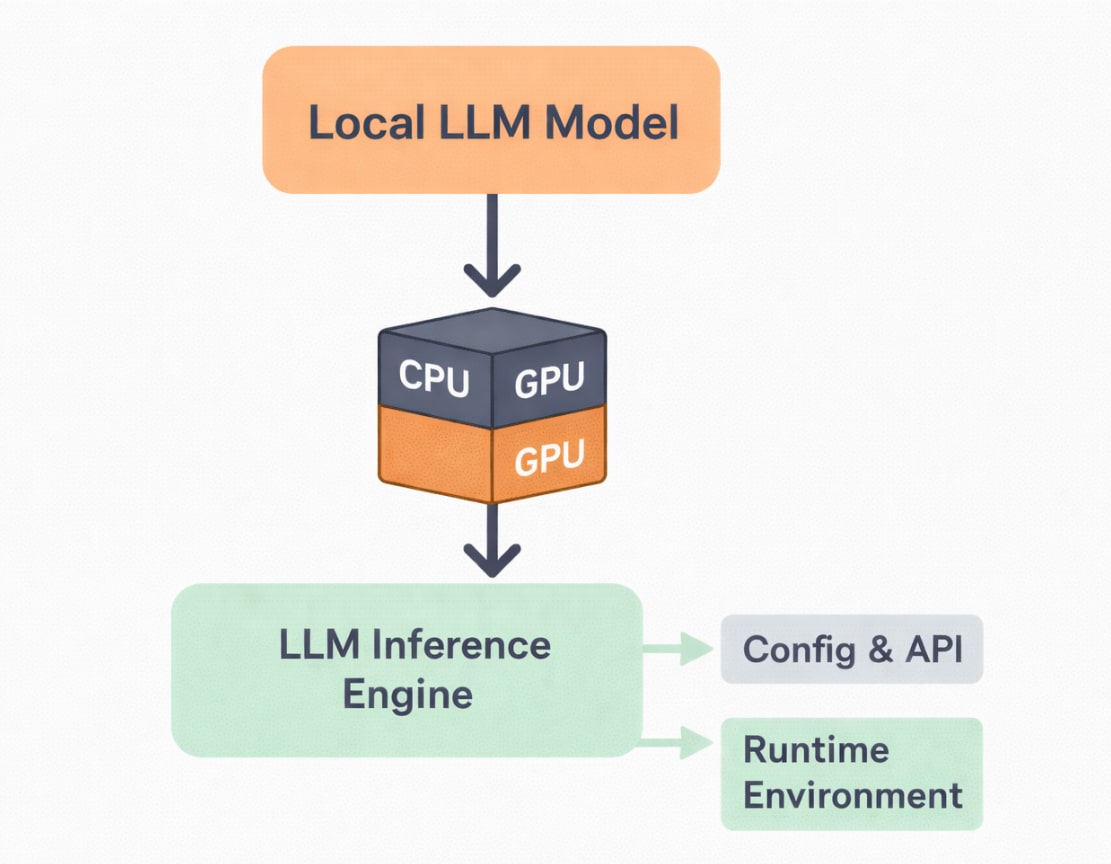
The software stack: Choosing your engine
Once the hardware foundation is in place, the real personality of a private AI assistant emerges from the software stack that powers it. Unlike cloud-based systems where infrastructure and tooling are hidden behind APIs, local deployments require conscious choices at every layer. The inference engine, model format, and runtime environment together determine how efficiently a language model runs and how flexible the system becomes over time.
At the core of the stack lies the inference engine, which is responsible for loading the model and executing predictions. Modern open source engines are designed to squeeze maximum performance from available hardware, whether that is a CPU, GPU, or a combination of both. These engines handle critical optimisations such as memory mapping, parallel execution, and hardware acceleration. Choosing the right engine often makes the difference between a sluggish assistant and one that feels responsive and natural.
Equally important is the model format itself. Large language models are distributed in various formats, each optimised for specific use cases. Lightweight formats reduce memory usage and enable faster loading, making them ideal for personal machines. Compression and quantization techniques further reduce resource requirements, allowing users to run surprisingly capable models on everyday hardware. This flexibility encourages experimentation, as models can be swapped or upgraded without rebuilding the entire system.
The surrounding runtime environment completes the stack. Language bindings, configuration files, and environment variables allow developers to fine-tune performance and behaviour. Open source ecosystems thrive on modularity, and local AI stacks are no exception. By combining well-supported tools, developers can build systems that are transparent, extensible, and easy to maintain. This modular approach ensures that a private AI assistant is not a static project but a living system that can evolve with new models and ideas.
Hands-on: Setting up the backend
With the hardware and software foundations in place, the next step is to bring the private AI assistant to life by setting up the backend. This backend acts as the intelligence layer of the system, responsible for loading the language model, managing prompts, and generating responses. Unlike cloud-based architectures that hide these details behind APIs, a local backend exposes the full lifecycle of inference, making it both transparent and highly customisable.
The process typically begins by loading a locally stored language model using the chosen inference engine. During initialisation, parameters such as model path, context length, and hardware preferences are defined. These settings determine how efficiently the model runs and how much system memory it consumes. Externalising configuration files at this stage makes the backend easier to tune and upgrade as newer models or optimisations become available.
Once initialised, the backend provides a simple interaction loop that accepts user input, applies system-level instructions, and returns generated responses. In many implementations, this logic is wrapped inside a lightweight local service so that the model can be accessed by different frontends without modification. The separation between the intelligence layer and the interface ensures flexibility and long-term maintainability.
A minimal example of such a backend interaction is shown below. It demonstrates how a local language model can be loaded and queried directly, without relying on any external services.
from local_llm import Model model = Model(model_path=”models/private_llm.bin”) system_prompt = “You are a private, offline AI assistant.” user_prompt = “Summarize the concept of sovereign AI.” response = model.generate( system_prompt=system_prompt, prompt=user_prompt, max_tokens=200 ) print(response)
This simple flow captures the essence of a local AI backend. The model resides entirely on the user’s machine, prompts are processed locally, and responses are generated without network access. While production systems often add layers such as request validation, logging, and session memory, the fundamental interaction remains straightforward and fully controlled by the user.
Equally important is how prompts are handled internally. User inputs are typically wrapped with predefined system instructions to ensure consistent behaviour across interactions. Because the entire pipeline runs offline, prompts and outputs never leave the device, reinforcing the privacy-first principles that motivate sovereign AI. At this stage, the assistant is no longer a conceptual idea but a functioning system capable of intelligent interaction.
Building the frontend: The assistant experience
Once the backend is operational, the focus shifts to the frontend, where the assistant becomes visible and usable. The frontend is not merely a visual layer but the medium through which users build trust and familiarity with the system. A well-designed interface can make even a complex AI system feel intuitive, while a poorly designed one can discourage use, regardless of how powerful the underlying model may be.
Most private AI assistants begin with a simple chat-style interface, as this mirrors natural human conversation. A text input area, a scrollable response window, and clear visual separation between user queries and assistant replies form the foundation of the experience. Because the assistant runs locally, the interface can be lightweight and responsive, without the overhead of handling authentication, network delays, or external API errors.
Beyond basic interaction, thoughtful design choices significantly enhance usability. Features such as conversation history, timestamped responses, and visual indicators during model processing help users understand what the system is doing. Since everything operates offline, these interactions feel immediate and predictable. The frontend can also be extended to support file uploads, allowing the assistant to summarise documents or answer questions based on local data, all without compromising privacy.
Importantly, the frontend and backend remain loosely coupled. The frontend simply sends prompts and receives responses, without needing to know how the model works internally. This separation allows developers to iterate on the user experience independently, experimenting with different layouts or platforms while keeping the intelligence layer intact. At this stage, the assistant evolves from a technical demonstration into a practical tool designed for everyday use.
Advanced configuration: Custom system prompts
Once the assistant is operational, its usefulness depends largely on how well its behaviour is defined. This is where system prompts play a critical role. A system prompt acts as the assistant’s foundational instruction set, shaping how it interprets queries, structures responses, and maintains consistency across interactions. Unlike user prompts, which vary from one request to another, system prompts remain persistent and quietly guide every output generated by the model.
Well-designed system prompts allow developers to establish clear expectations for the assistant’s role and tone. An assistant can be instructed to remain concise, avoid speculation, or focus on a specific domain such as programming, research, or documentation. Because the model runs locally, these instructions are fully visible and editable, allowing users to refine behaviour without external moderation layers or hidden constraints.
A simple example of a system prompt used in a private AI assistant is shown below. This prompt defines the assistant’s role, tone, and boundaries in a way that remains active throughout the session.
You are a private, offline AI assistant running on a local machine.
Respond clearly and concisely using simple language.
Do not assume internet access or reference external services.
If information is uncertain, state the limitation explicitly.
Prioritise user privacy and avoid generating sensitive content.
This single block of text has a significant impact on the assistant’s behaviour. It ensures predictable responses, discourages hallucination, and reinforces the offline nature of the system. As prompts become more refined, developers can introduce contextual instructions, task-specific roles, or dynamic modifications based on user activity, allowing the assistant to adapt intelligently without changing the underlying model.
The ability to iterate freely is one of the greatest strengths of local AI systems. Prompt variations can be tested instantly, evaluated in real time, and adjusted until the assistant aligns perfectly with user expectations. This level of control transforms prompt engineering from an abstract concept into a practical tool, reinforcing the broader promise of sovereign AI through transparency, adaptability, and ownership.
The future of offline intelligence
The rapid rise of generative AI has reshaped how we interact with machines, but it has also forced us to reconsider where intelligence should reside. While cloud-based systems will continue to play a major role, the growing capability of local large language models signals a meaningful shift. Intelligence no longer needs to be centralised to be powerful. With the right tools and configurations, it can exist directly on personal devices, operating independently and securely.
Building a private AI assistant using local LLMs demonstrates what this shift looks like in practice. It shows that advanced AI systems can be transparent, customisable, and respectful of user privacy without sacrificing usability. By controlling the hardware, software stack, and behavioural configuration, users gain a level of autonomy that is rarely possible with hosted solutions. This autonomy is particularly important in domains where data sensitivity and reliability are critical.
As open source models continue to improve, and as hardware becomes more efficient, offline AI systems will only grow more capable. What is experimental today will soon become mainstream, powering personal assistants, research tools, and productivity systems that function entirely on-device. This evolution aligns closely with the broader principles of open source software, where trust is built through visibility, collaboration, and shared ownership.
The future of artificial intelligence is not defined solely by scale, but by control. Local LLMs and private AI assistants offer a compelling alternative to cloud dependence, proving that intelligence can be both powerful and personal. For developers, students, and organisations alike, this represents an opportunity to rethink how AI is built and who ultimately owns it.


