






























































This overview of popular tools for monitoring large language models also sheds light on how LLM-as-a-judge enhances their performance.
It’s no secret that, these days, the corporate world as well as the government sector is using AI chatbots and large language models (LLMs) for data analytics and decision making. The key strengths of AI chatbots that use LLMs include multimodal search, content creation, programming, applications development, coding, scripting, multimedia creation, task automations, academic research, speech analytics, and data engineering.
In India, many MNCs as well as domestic IT companies are working on the development and deployment of AI chatbots for different applications. As per a report by the Bank of America, cited in The Economic Times, India is a leader in the adoption and implementation of AI models.
Table 1: Popular AI chatbots for different applications
| ChatGPT | Gemini |
| Chatbot | Claude |
| Perplexity | Microsoft Copilot |
| Meta AI | Grok |
| Pi | Qwen Chat |
| Mistral Chat | YouChat |
| Ernie Bot | HuggingChat |
| Character.AI | Jasper Chat |
| Baichuan Chat | Writesonic Chat |
| Bing Chat | DeepSeek Chat |
| TII Falcon Chat | Replika |
| Kimi | SenseChat |
| Suno AI Chat | Yi Chat |
| ChatGLM | ChatPDF |

LLM-as-a-judge: Observation, monitoring and analytics of LLM platforms
LLM-as-a-judge is a technology for evaluating the performance of AI LLMs in terms of effectiveness of prompts, tokens used, cost factor, and many other parameters that directly affect the execution of the deployment.
The LLM-as-a-judge service provides observation and analytics with use cases centered on prompt lifecycle management—including assessing prompt effectiveness, ensuring traceability and versioning, and analysing cost factors—alongside operational monitoring of latency and token accounting. Key advantages are robust governance and quality assurance, offering comprehensive response auditing, error diagnosis, and outcome visibility with capabilities for hallucination detection and regression testing. Furthermore, it enables rigorous model evaluation through comparison, drift detection, and scoring, while ensuring reliability and compliance via reproducible experiments, audit-ready evidence, and governance readiness, all supported by vendor-neutral debugging pipelines and secure offline deployments.
Several tools are available for observability and analytics of AI LLMs for the cloud as well as for dedicated deployment on site (Table 2). Using these tools, the performance of LLMs can be evaluated and optimised.
Table 2: Key tools for performance evaluation and analytics of LLMs
| Name | Core modules/ Capabilities | Key applications | URL |
| Comet Opik | Prompt/response logging, trace visualisation, experiment tracking, evaluations, OpenTelemetry support | LLM observability, evaluation and debugging | comet.com/opik |
| OpenLit | OpenTelemetry instrumentation, LLM spans, latency and token metrics, vendor-agnostic | LLM observability, tracing, prompt/response monitoring | openlit.io |
| OpenTelemetry | Traces, metrics, logs, exporters (Jaeger, Prometheus, console) | Unified observability backbone | opentelemetry.io |
| Helicone | Request proxying, latency analysis, prompt logs, error monitoring | LLM request monitoring and debugging | helicone.ai |
| Langfuse | Prompt versioning, trace trees, scoring, datasets, feedback loops | Prompt tracking, cost analysis, evaluations | langfuse.com |
| Promptfoo | Regression testing, prompt scoring, multi-model evals | Prompt testing and comparison | promptfoo.dev |
| Traceloop | OpenTelemetry-native tracing, framework integrations (LangChain, LlamaIndex) | LLM pipeline tracing | traceloop.com |
| Phoenix | Embedding drift, trace visualisation, evaluation dashboards | LLM quality and hallucination analysis | phoenix.arize.com/ |
| Ragas | Faithfulness, relevance, context precision/recall | RAG and LLM output evaluation | github.com/explodinggradients/ragas |
| Evidently AI | Drift detection, data quality, evaluation reports | Data and model monitoring | evidentlyai.com |
| MLflow | Runs, metrics, artifacts, model registry | Experiment tracking (LLM-adaptable) | mlflow.org |
| DeepEval | Test cases, metrics, CI/CD-ready evaluation | Unit testing for LLMs | github.com/confident-ai/deepeval |
| Jaeger | End-to-end request tracing, span timelines | Trace visualisation | jaegertracing.io |
| Prometheus | Time-series metrics, alerting | Metrics monitoring | prometheus.io |
| Grafana | Traces, metrics, logs dashboards | Visualisation and dashboards | grafana.com |
| Ollama | Local model serving, OpenAI-compatible API | Offline/local LLM execution | ollama.com |
Working with Comet Opik
(comet.com/opik, comet.com/site/products/opik/)
Comet Opik is a powerful and multi-featured platform for observability, analytics and evaluation of LLMs, including prompts.
Opik provides a range of features for debugging, evaluating and monitoring LLM applications, RAG implementations and agentic AI based workflows so that tracing and metrics analytics can be done effectively for enhancing the overall performance of the deployment. It integrates optimisation and benchmarking features with ease of implementation.
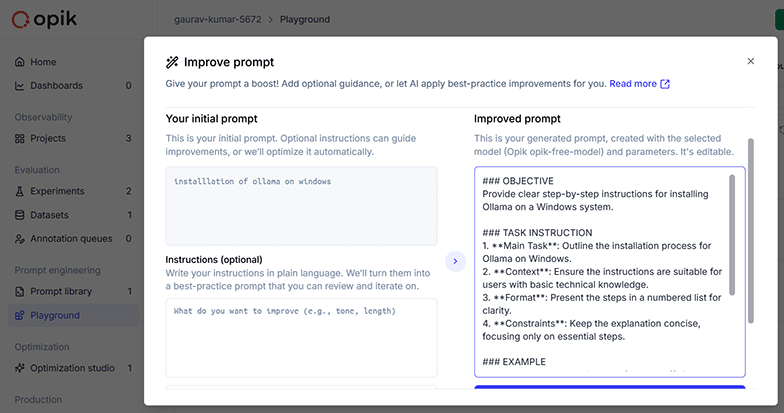
Comet Opik is available for cloud as well as dedicated deployments. Here’s how to install it on Windows:
git clone https://github.com/comet-ml/opik.git cd opik powershell -ExecutionPolicy ByPass -c “.\opik.ps1”
To install on Linux/Mac, use the following code:
git clone https://github.com/comet-ml/opik.git cd opik ./opik.sh Opik URL for Access: http://localhost:5173
The cloud deployment of Opik is available at comet.com/opik.
Key features
The Comet Opik platform offers a comprehensive suite of features for the analytics and optimisation of LLMs, including using an LLM as a judge, detailed trace visualisation, and OpenTelemetry support for robust monitoring. It enables complete experiment management through prompt logging, reproducible runs, and dataset versioning, while providing deep analytical tools for optimisation factors analysis, LLM comparisons, and metric customisation. The platform ensures rigorous evaluation via customisable workflows, response tracking, and judge scoring, and supports governance and research alignment with capabilities for bias inspection, error analysis, drift analysis, and audit trails, all with offline compatibility for secure and flexible operation.
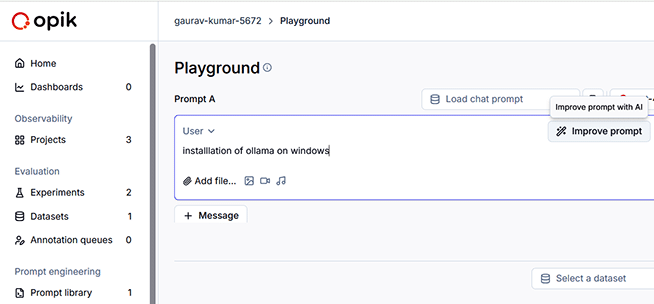
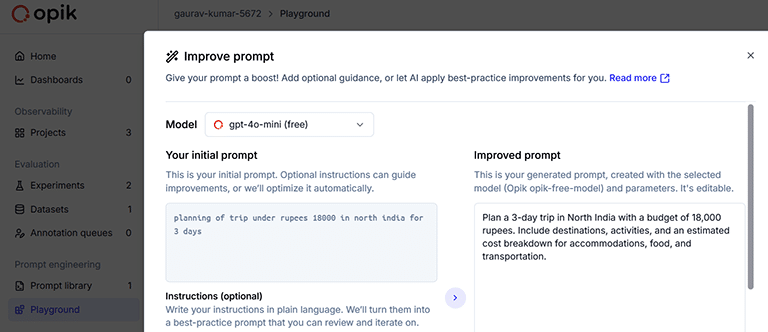
LLM prompts can be improved using Comet Opik so that the desired results can be fetched from AI LLMs.
Often, users of AI applications give a prompt in their own natural or casual language. Such prompts can be analysed and further improved with optimisation evaluations in Opik.
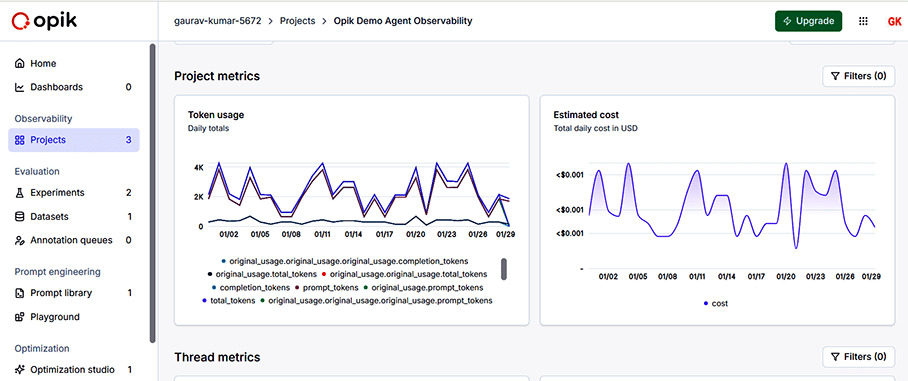
Project executions on Opik can be analysed in terms of different types of graphs and plots so that the analytics can be used for further improvement or optimisation.
LLM-as-a-judge platforms can be used by researchers and practitioners who are working on resource optimisation so that AI LLMs can be developed and deployed with limited or minimal resources.


















{kind=link}