






























































In this first part of a two-part series, discover why we need to fine-tune large language models, and get introduced to the core concepts and techniques used for their domain-specific adaptation.
Large language models (LLMs) are deep neural networks, typically based on the Transformer architecture, trained on massive text corpora to predict the next token in a sequence. These models can generate text, write code, summarise documents, and answer complex questions. However, a general-purpose LLM cannot automatically perform well in specialised domains such as finance, healthcare, legal compliance, or enterprise-specific tasks. This limitation creates the need for LLM adaptation, where a pre-trained model is modified to behave correctly for domain-specific use cases.
Approaches to LLM adaptation
LLMs often need adaptation for two main reasons. The first is the limitations of base models — pre‑trained models possess generic knowledge and may produce inaccurate or contextually irrelevant responses (i.e., prone to hallucinations). The second reason is the need for customisation, as enterprises require outputs that follow internal standards — specific tone, formats, templates, and regulatory language.
There are three main approaches to adapting an LLM: prompt engineering, RAG, and fine‑tuning.
Prompt engineering
Prompt engineering adjusts the model’s behaviour through carefully crafted instructions without changing the model itself. It is best suited for quick behavioural adjustments in situations where the base model already has sufficient domain knowledge.
RAG (retrieval-augmented generation)
RAG enriches the model’s responses by retrieving relevant external documents and injecting them into the prompt at inference time. This enables the model to generate knowledge-based answers using fresh or domain-specific information without requiring retraining.
Fine-tuning
Fine-tuning updates the model’s parameters using domain-specific datasets, so it learns terminology, style, and task patterns internally. It is used for deep domain expertise or specialised tasks where consistency and precision are essential.
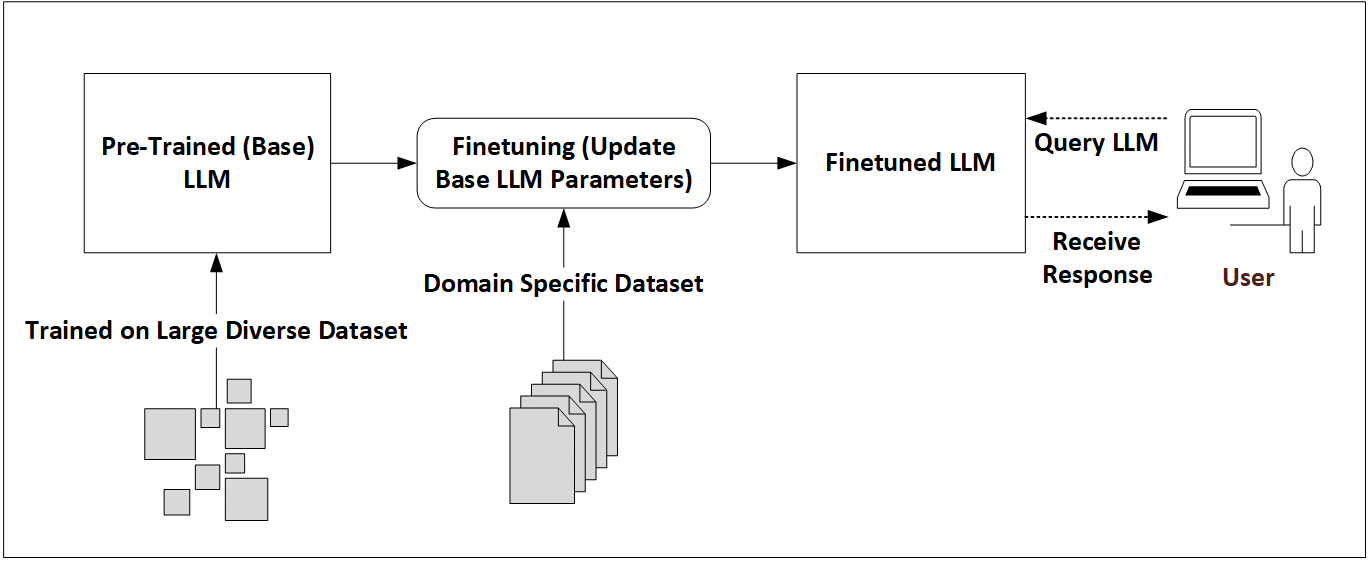
What is fine-tuning?
Fine‑tuning involves taking a pre‑trained LLM and further training it on a focused, domain‑specific dataset. During fine‑tuning, some or all the model’s parameters are adjusted so it can learn the domain’s terminology, style, and reasoning patterns. This focused training helps the model go beyond generic knowledge and develop a more expert understanding of how information is expressed and interpreted in that field.
Fine‑tuning is required over prompt engineering and RAG as:
- Prompt engineering can guide a model but cannot force it to learn domain terminology or internal workflows it has never seen.
- RAG augments the model with retrieved documents, but it doesn’t change model behaviour.
- Prompts and retrieved documents cannot guarantee deterministic and compliant behaviour. Fine‑tuning allows embedding organisational compliance directly into the model parameters.
Types of fine-tuning
Based on the training objective and kind of data used, fine tuning can be categorised as unsupervised fine‑tuning, supervised fine‑tuning (SFT) and instruction fine‑tuning (IFT).
Unsupervised fine-tuning
Unsupervised fine‑tuning involves training the model further on raw, unlabelled text from a specific domain. It does not teach the model specific tasks; instead, it strengthens domain understanding, reduces hallucinations, and improves fluency.
Example use cases are:
- Adapting a general LLM to understand medical literature.
- Training on legal contracts to learn clause structure, legal terminology, and formal writing style.
Supervised fine‑tuning (SFT)
The goal of SFT is to teach the model how to perform a specific task using labelled input-output pairs. Each training example consists of an input prompt and a desired response. The focus is on learning patterns, formats, and decision logic for a particular workflow.
Unlike unsupervised fine-tuning, SFT explicitly guides the model towards correct behaviour and output generation for well-defined workflows.
Example use cases are:
- Training a code-generation model using problem–solution pairs.
- Adapting a model for news classification.
Instruction fine-tuning (IFT)
Instruction fine-tuning (IFT) is a specialised form of supervised fine-tuning in which the input is an explicit natural language instruction, followed by the expected response. The goal of IFT is to train the model to understand and follow human instructions reliably across a wide range of tasks.
IFT improves conversational ability, task compliance, and reasoning behaviour, making it a key technique behind modern chat-based LLMs. Popular open source models such as LLaMA-Instruct and Mistral-Instruct rely heavily on IFT. IFT is typically the final fine-tuning stage before deploying an LLM for interactive applications.
Example use cases are:
- Training a chatbot to respond in a specific tone or writing style.
- Training the model to respond safely and refuse invalid or harmful requests.
Techniques of fine-tuning
Fine‑tuning methods can be divided into two broad technical approaches depending on how much of the model is updated and the computational cost involved. These approaches are full fine‑tuning and parameter‑efficient fine‑tuning (PEFT).
Full fine‑tuning
Full fine‑tuning involves updating all the parameters of the pre-trained LLM during training. The entire LLM (billions of parameters) is unfrozen and learns the new domain end‑to‑end. It provides the highest level of adaptation and can significantly change model behaviour. It requires large compute resources and substantial training data. However, it can carry risks of overfitting and catastrophic forgetting.
Full fine-tuning can be used:
- When the domain is very different from the general knowledge of the model (e.g., biomedical, aerospace domains).
- When maximum accuracy and deep adaptation are needed.
- When compute resources and large training datasets are available.
| Note: Overfitting: The model may memorise training examples instead of learning general patterns if the dataset is too narrow/small. The model performs perfectly on the training examples but loses its ability to handle new and unseen data. Catastrophic forgetting: The model may lose general capabilities because new training overwrites pre‑training knowledge. |
Parameter‑efficient fine‑tuning (PEFT)
Parameter-efficient fine-tuning (PEFT) updates only a small subset of the model’s parameters while keeping the base pre-trained model frozen. This approach significantly reduces training costs, GPU memory usage, and the overall time required for fine-tuning.
Instead of modifying billions of parameters, PEFT techniques add lightweight trainable components, such as low-rank matrices, adapter layers, or learned prompts to the existing model. These components learn task-specific behaviour while preserving the general knowledge already present in the base model. As a result, PEFT makes fine-tuning practical even on limited hardware and is widely adopted in the open source community.
PEFT can be used:
- When compute resources are limited (single GPU or consumer-grade hardware).
- When multiple task-specific models need to be derived from a single base LLM.
- When fast experimentation and iteration are required.
- When preserving the base model’s general knowledge is important.
Some commonly used PEFT techniques include LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA).
LoRA (Low-Rank Adaptation): LoRA introduces small trainable low-rank matrices into selected Transformer layers. During training, only these added matrices are updated, while the original model weights remain frozen. This greatly reduces the number of trainable parameters without significantly affecting model performance. Use LoRA when you need general enterprise fine‑tuning with moderate domain data and want high accuracy at low training cost.
This is how LoRA works internally:
- During fine‑tuning, the base model weights remain frozen (W₀), and LoRA learns only a small task‑specific update (ΔW). The updated weight used by the model is:
W = W₀ + ΔW
- Instead of learning a large d × d update matrix, LoRA represents the update in a compact low‑rank form:
ΔW = BA
Here:
d = the model’s hidden size (its internal feature dimension)
A = a small matrix with r rows and d columns
B = a small matrix with d rows and r columns
r = the low rank (a small number compared to d; typically, 4, 8, or 16)
- This reduces trainable parameters from d² to 2dr, making training faster, cheaper, and more memory‑efficient while maintaining strong accuracy.
QLoRA: QLoRA extends LoRA by loading the base model in 4-bit quantized precision, which further reduces GPU memory usage. The LoRA components remain in higher precision and are trained normally. This combination enables fine-tuning of very large models (30B-70B parameters) on a single GPU. Use QLoRA when training large models (13B-70B) on limited hardware; 4‑bit quantization reduces memory while preserving model quality.
| Note: Low-rank matrix: A compact mathematical representation that approximates large weight updates using much smaller matrices, reducing memory and computation. Quantization (4-bit): A technique that stores model weights using fewer bits (4 instead of 16 or 32), lowering memory usage with minimal loss in accuracy. |
This first article in the two-part series has established the foundation for understanding how and why large language models must be adapted for real‑world, domain‑specific use cases. With this conceptual grounding, the next part will demonstrate a complete hands‑on workflow for fine‑tuning an open source LLM (Mistral-7B-Instruct) using PEFT QLoRA in Google Colab environment.


















{kind=link}