






























































GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. It is an open source data query language. Developed by Facebook in 2012 for its own use, it was moved to the Graph QL Foundation in 2018.
In this article, let us explore GraphQL (https://graphql.org/), which is a specification from Facebook. GraphQL is a query language for APIs and a runtime for fulfilling those API queries with your existing data. It gives clients the power to ask for exactly what they need and nothing more, by avoiding over-fetching or under-fetching of data. We can understand it more when we see GraphQL implementation in action. Till then, restrain your curiosity. So far we have been using REST (Representation State Transfer) to expose our services as APIs. Let us ask ourselves some questions before going deeper into GraphQL.
![]()
 Why do I need to adopt GraphQL?
Why do I need to adopt GraphQL?
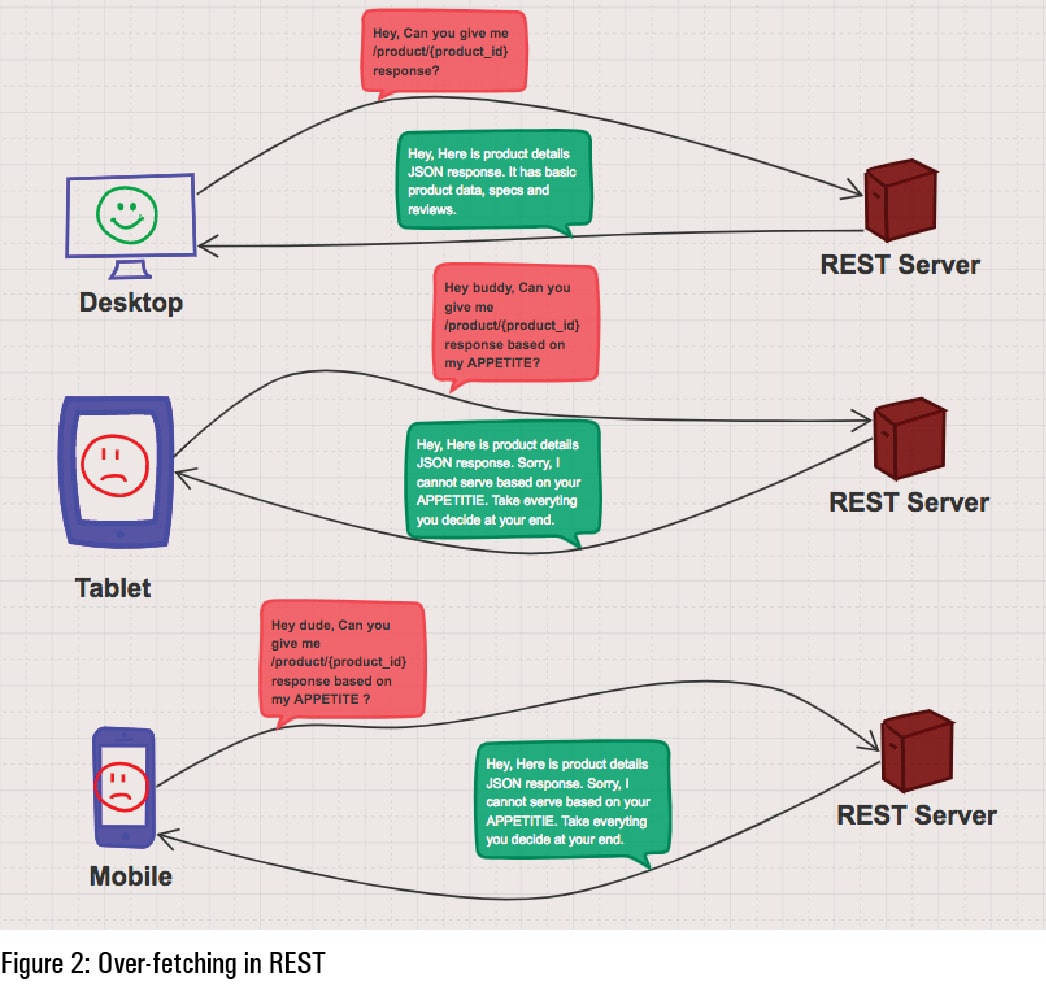
What problems am I facing with REST APIs and how does GraphQL solve them? To answer these queries, let us take a use case of building an e-commerce application for the Web, mobile and native clients. Let’s first expose APIs for various e-commerce functionalities. For example, I have the product detail REST API, which gives specific product information as JSON — this includes product data attributes, specifications data, reviews data, etc. As we have many attributes in product JSON, this is larger in size. Each client (Web and thin client — mobile and tablets) has its own front-end requirements to display product data, as each has different screen sizes, memory, network bandwidth, etc. Now, the clients start consuming the product detail API. Though mobile and tablet interfaces don’t require the entire product JSON as Web does, even then the product detail API gives the entire product data. It is evident that clients don’t have control over the data they want from the server. This is called over-fetching. The pictorial representation of the REST over-fetching issue is shown in Figure 2.
We can solve the over-fetching issue with various approaches. The straightforward approach is to maintain different APIs for thick and thin clients. Though this design solves the over-fetching issue, there are other problems like code maintenance, implementation of enhancements across different APIs, deployment of thick/thin client APIs, more compute, more manpower, etc, which increases the cost of the project. The other approach is having middleware to intercept the client request. Based on the client request, we can filter the response to return. But this adds an additional layer to the application, which has the same issues as the previous approach.
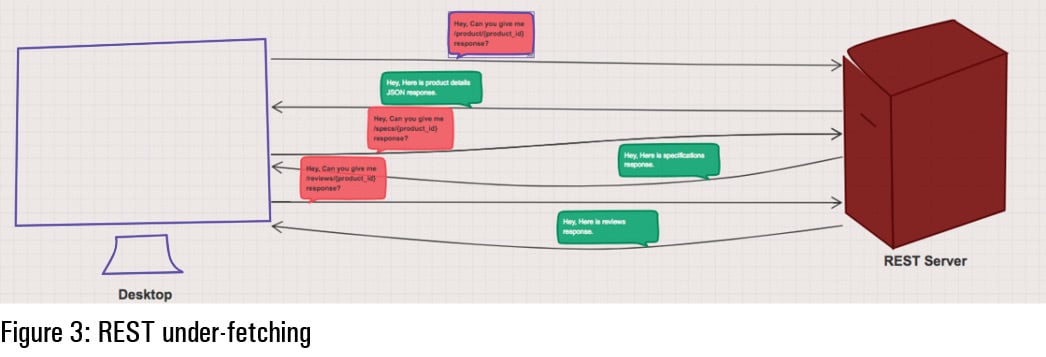
Now let us discuss the second issue with REST, which is called under-fetching. To avoid over-fetching, we can create granular APIs so that clients can make API calls for whatever data they require. Let us consider the product detail page for the Web. It has product information, specifications and reviews to display. Now, to render the product detail page, the client is not going to get data in a single API call. So, clients need to make multiple API calls (like the basic product API, the specification API, the reviews API, etc) to cater to their data requirement. This design has performance issues because of the increased number of round trips to the back-end server and API gateway. The other issue is the requirement of more compute power and networks to cater to the rise in the number of requests to serve. A pictorial representation of under-fetching is shown in Figure 3.
 Let us look at the third issue with REST, which is, APIs with new versions. Any API evolves as business needs change with time. As per our customers’ needs, we might need to add data attributes (in most cases we won’t remove data attributes as we need to have backward compatibility) to existing APIs. When we make any changes to existing APIs, we need to be extra vigilant as the changes might break the clients. To avoid that, we do versioning of APIs as and when we plan to release changes to existing APIs. When we introduce new versions, we need to manage more APIs (i.e., more compute power and more manpower), and also have to plan how to deprecate older versions. Discipline and communication are needed when we have more versions of an API. With REST, we cannot do silent releases.
Let us look at the third issue with REST, which is, APIs with new versions. Any API evolves as business needs change with time. As per our customers’ needs, we might need to add data attributes (in most cases we won’t remove data attributes as we need to have backward compatibility) to existing APIs. When we make any changes to existing APIs, we need to be extra vigilant as the changes might break the clients. To avoid that, we do versioning of APIs as and when we plan to release changes to existing APIs. When we introduce new versions, we need to manage more APIs (i.e., more compute power and more manpower), and also have to plan how to deprecate older versions. Discipline and communication are needed when we have more versions of an API. With REST, we cannot do silent releases.
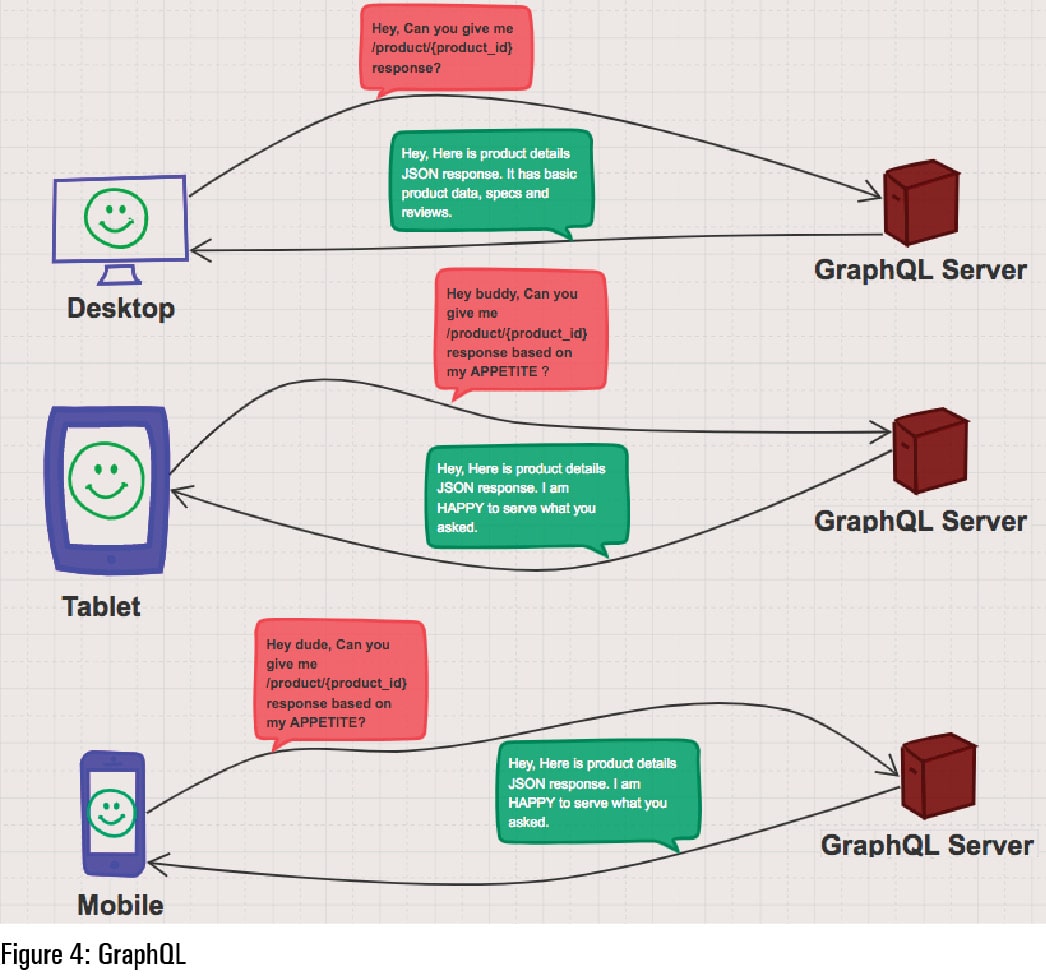
There is another solution called GraphQL that can help here. We will look at how GraphQL addresses the issues discussed in an upcoming article. Meanwhile, let us check out the request and response paradigm with GraphQL, and how the latter makes clients happy by serving them what they want.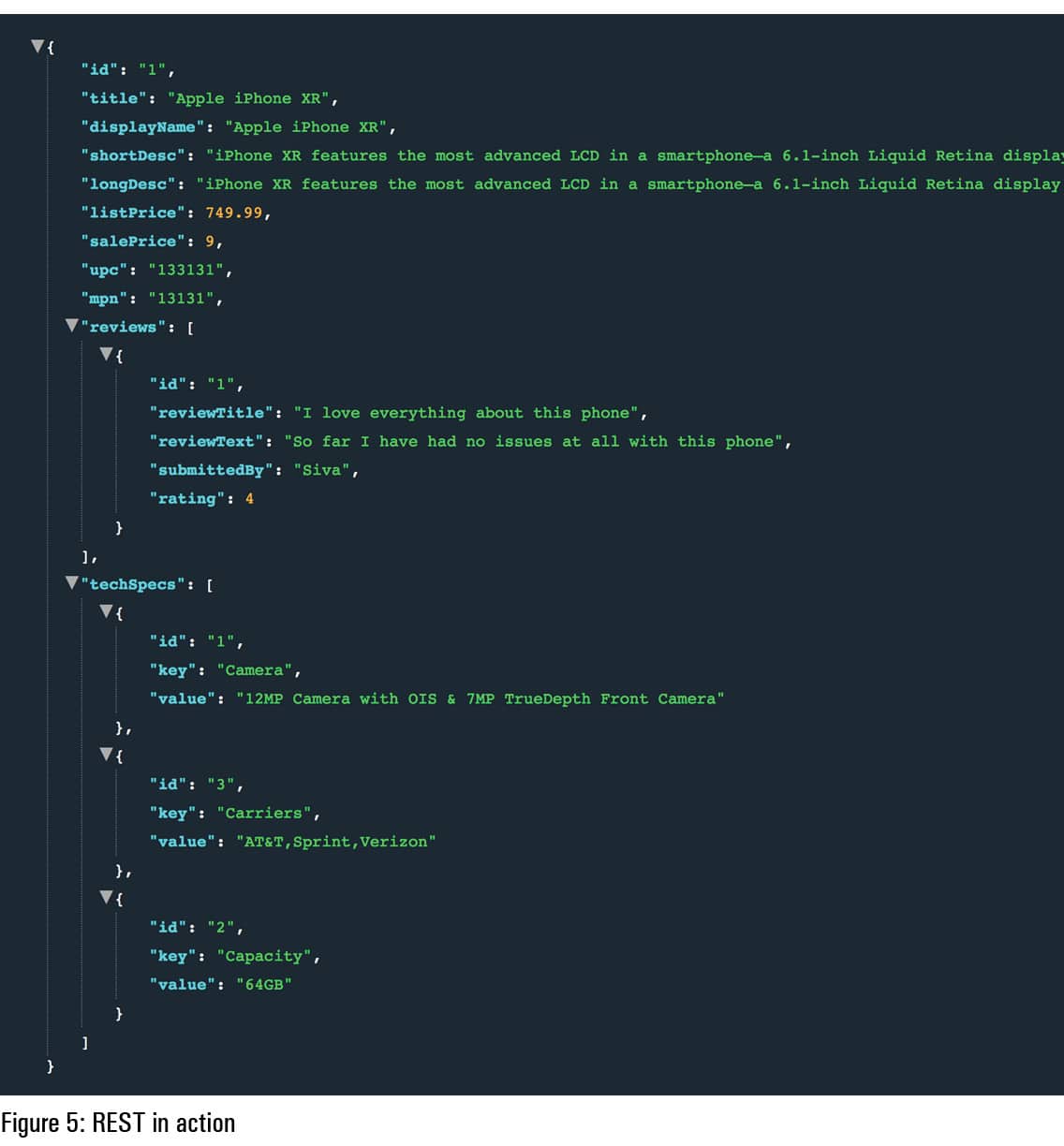 Some entities that have adopted GraphQL are listed at https://graphql.org/users/.
Some entities that have adopted GraphQL are listed at https://graphql.org/users/.
I have created a sample application to showcase the differences between REST and GraphQL. First, we will look at the REST implementation of a simple product detail end point. I have used Spring Boot to demonstrate REST. You can download the sample project from https://github.com/2013techsmarts/Code_Samples/tree/master/rest-demo, and follow the steps outlined in the README (https://github.com/2013techsmarts/Code_Samples/blob/master/README.md) to set up the project. I am not discussing setup details here as it is beyond the scope of this article. Assuming that your project is up and running, make a call to http://localhost:8080/product/{product_id} endpoint to get product detail JSON, as shown in Figure 5.
You may have observed that JSON delivers the entire product JSON, including reviews and technical specifications, though we are not interested in all the elements of a given product.
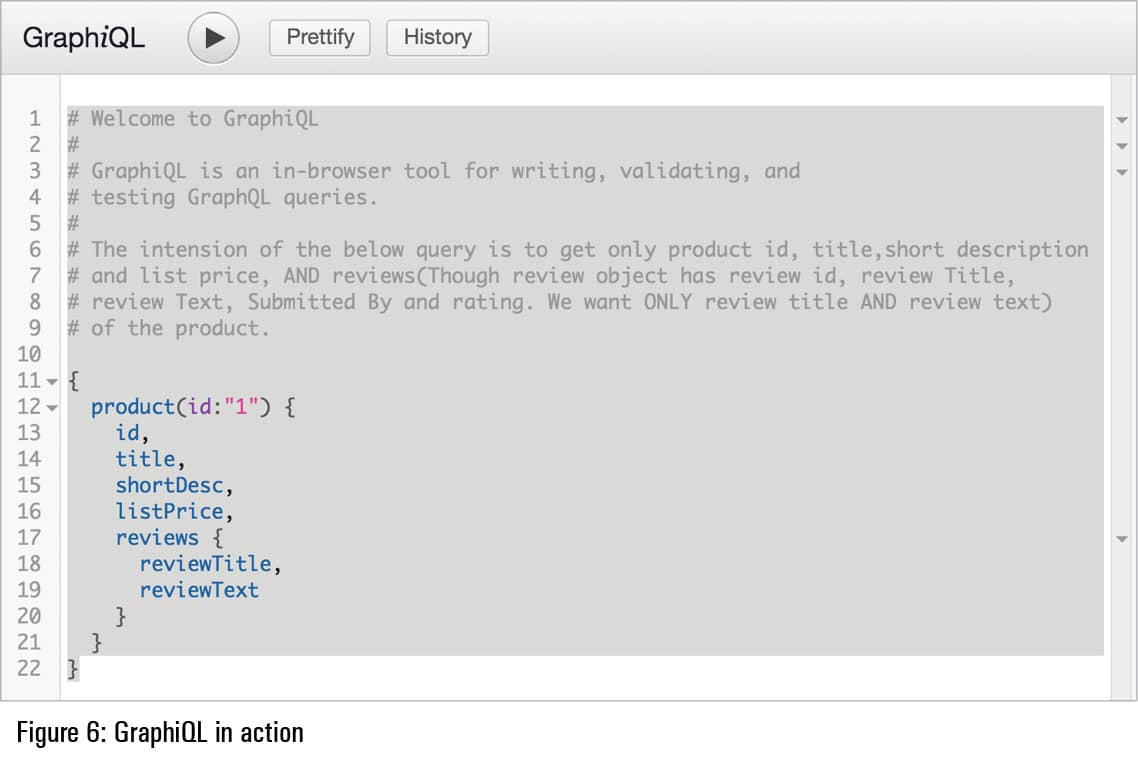 Let us now look at GraphQL in action by getting product details in a selective manner. To demonstrate GraphQL, I again used Spring Boot. You can download the sample project from https://github.com/2013techsmarts/Code_Samples/tree/master/graphql-demo, and follow the steps outlined in the README (https://github.com/2013techsmarts/Code_Samples/blob/master/README.md) to set up the project. I am not discussing setup details here as that is beyond the scope of this article.
Let us now look at GraphQL in action by getting product details in a selective manner. To demonstrate GraphQL, I again used Spring Boot. You can download the sample project from https://github.com/2013techsmarts/Code_Samples/tree/master/graphql-demo, and follow the steps outlined in the README (https://github.com/2013techsmarts/Code_Samples/blob/master/README.md) to set up the project. I am not discussing setup details here as that is beyond the scope of this article.
I am assuming that your project is up and running so you can see GraphQL in action, in which case I am interested to get only the product ID, the title, a short description and list price of a given product. Let us see how we can query to get the other details we’re interested in.
To demonstrate GraphQL I have used the GUI based plugin GraphiQL. For consuming from other applications, we can configure the endpoint in application.properties.
graphql.servlet.mapping=/graphql graphql.servlet.enabled=true graphql.servlet.corsEnabled=true
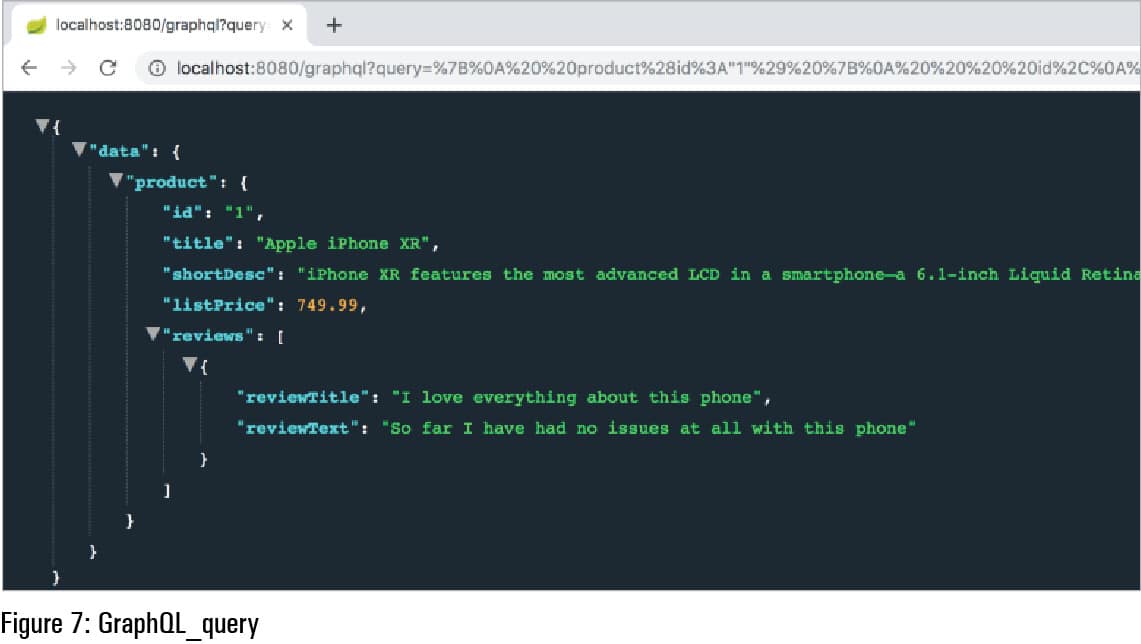
Now we can make a call to the above endpoint by passing a URL encoded query parameter as shown in Figure 7. You can learn more about queries and mutations at https://graphql.org/learn/queries/.

















{kind=link}