






























































While building an app, you need to manage environment variables and preserve their credentials. SecretsFoundry helps you to automatically fetch these variables from different secret managers, helping to make configurations across environments seamless.
One of the biggest challenges in application development is managing environment variables and preserving their credentials. Let’s go over different approaches in detail. Imagine you are building a simple app that talks to a MongoDB database through a connection and starts serving on port 3000. As easy as it sounds, it is very wrong to hard-code credentials inside the code, as it will then run only on the specified system where it has been coded. Even if shared with fellow engineers, the code will not be able to connect with the MongoDB instance or run in different deployed environments.
server = Server()
mongoDB = new MongoDb(“mongodb://username: password@locahost:3000/testdb”)
server.get(‘/users’, function() {
mongoDB.getUsers()
})
server.start(port=3000)
While cross-environment configurations are pain points, following the 12 factor app methodology helps in separating them from the code. Your configuration comprises credentials that talk to the backend services (SQL, MongoDB or Memcached). There can also be credentials that talk to different APIs if the code is interacting with Twitter or Amazon S3 APIs. There can be host names or ports that can vary across deployments, but this should be a part of the configuration.
What is 12 factor app methodology?
|

Defining environment variables
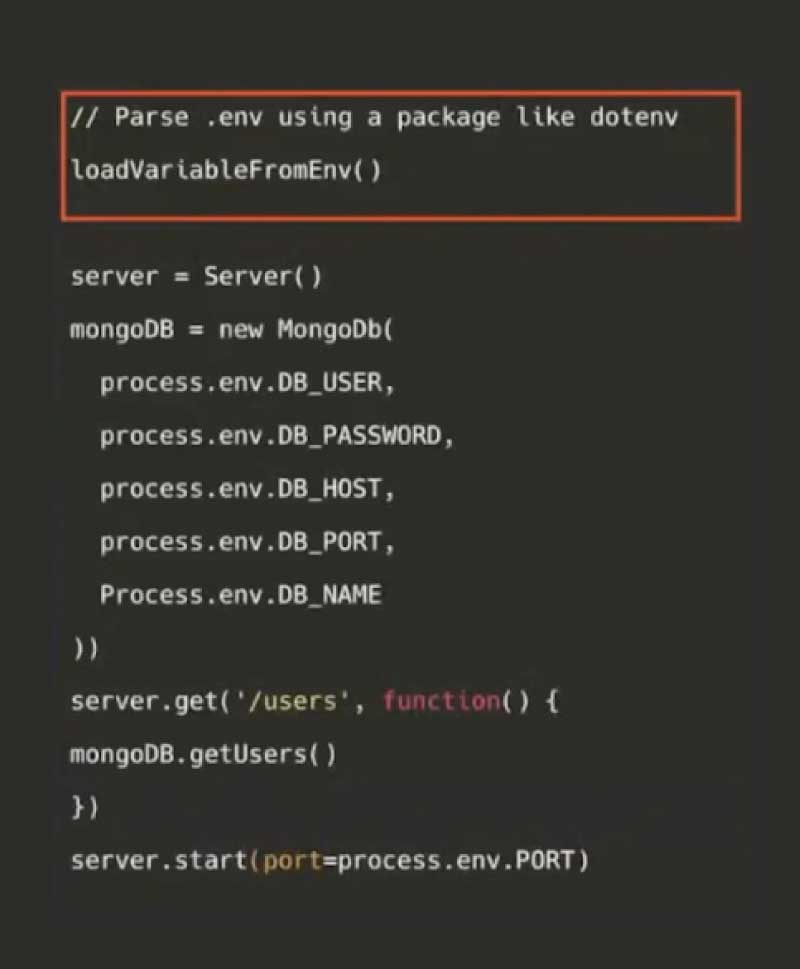
Generally, defining environment variables is OS-dependent, but programming languages have now abstracted away such differences using development packages like Python’s dotenv (.env). A dotenv file can manage environment variables across dev environments, allowing the developer to use locally managed configuration files. After abstracting the configuration of code to a different env file, the code loads all variables from an env file.
The code is modified and MongoDB now uses the environment variables to connect to itself, making the code run in different places with a custom dotenv file.
Deploying code to production
When the code is to be shifted to production, where you have a MongoDB production instance, you have to compose the dotenv file and copy the credentials of MongoDB to it. Similarly, you need to copy all the environment variables and send them to the deployment infrastructure. For example, the developer using Kubernetes will somehow have to set all the environment variables in it, and configure maps and secrets. For instance, an AWS ECS requires you to set that configuration in Fargate, and AWS Elastic Beanstalk has its own console for you to copy the environment variables.
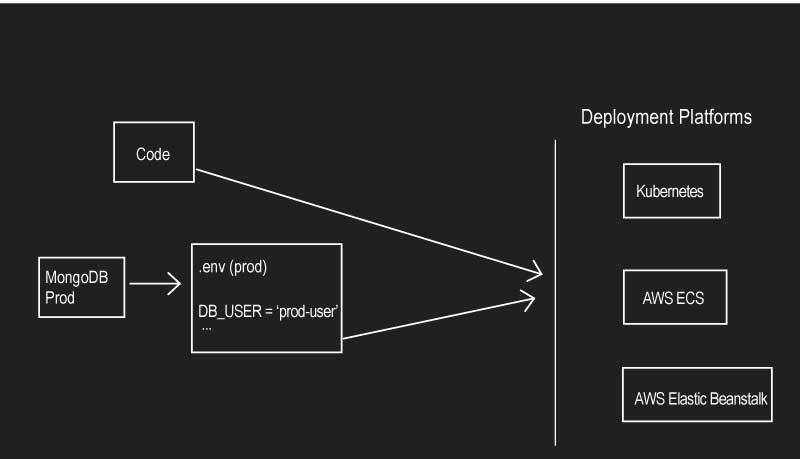
The variables for production environments are fed manually to the deployment infra, which is awful. For every single app built, there is a manual process to copy variables into the deployment infrastructure. This is not a one-time process — every time a developer adds or deletes an environmental variable, it has to be further communicated to the DevOps team, and the latter either adds the variable or removes it from the production system. This is a slow manual cycle, and handling multiple apps with multiple environments becomes an extremely tedious and error-prone process.
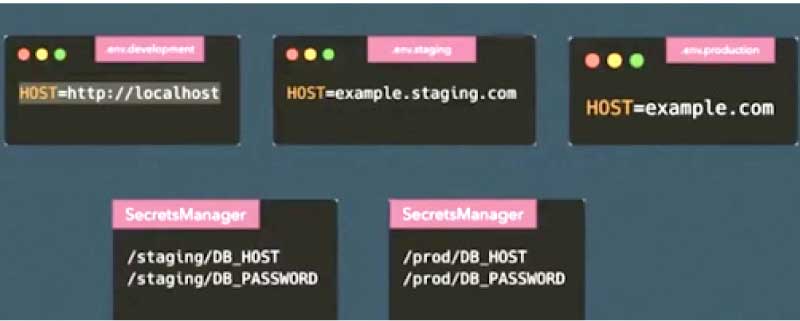
A scalable solution is to create a dotenv file per environment for development, staging and production, as shown in Figure 4. We overwrite all the values and build a system that can just ship this file to the deployment infrastructure.
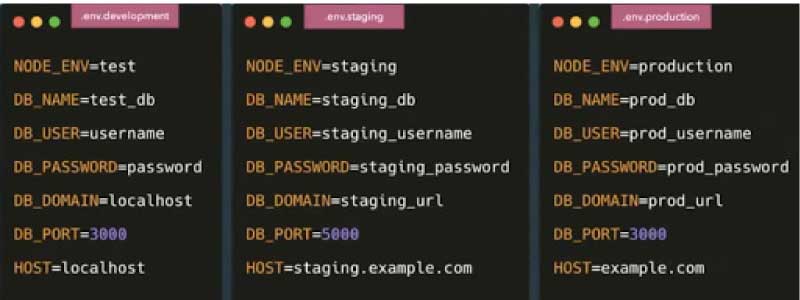
The whole process is now automated, and you just have to change the file and automatically sync to any deployment system that is being used. Once you have separate dotenv files, you can simply modify the code to load from whichever stage of production.
After getting the configuration, you can just call the MongoDB connection with config variables. The configuration should be written separately for every single environment and committed to the GitHub repository. Then, as the code is deployed using the continuous integration/continuous delivery (CI/CD) pipeline, it automatically loads the environment variables and runs, with no manual communication needed between the DevOps and engineering teams.
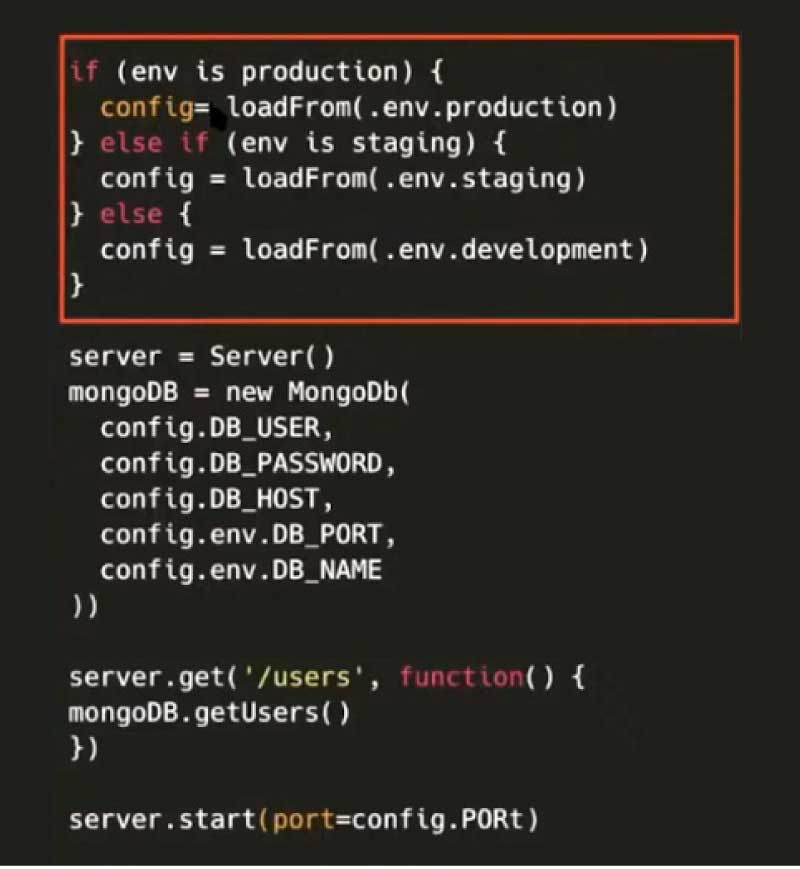
The dotenv file should be committed to Git and the environment variable must be set once in the deployment infrastructure manually. For the rest of the future deployments, the code will automatically run by passing on the variables.
The problem here is the need to put all these credentials for the production database in the dotenv production file and also commit it to Git. This is a huge security risk as you are sharing secret credentials with everyone in the project. There is the risk of any hacker getting access to the Git repository, even if you are working alone. Hence, fundamentally, never store credentials in plain text, or send them over Slack or any other messaging medium.
One solution here is to use a secrets manager, which will encrypt secrets and also have an access control built into it. So when the code asks for the encrypted key, the secrets manager automatically decrypts it and returns to the value. This allows you to manage permissions to people having access to the secrets, making the code more secure.
There are some secret managers that even provide active support for rotating secrets. For example, if the database credentials are stored in a secrets manager, the latter can automatically rotate these credentials every six months. So all the apps using the credentials from the secrets manager will start receiving the new ones after six months, and the database will also move to the new credentials. AWS Parameter Store, AWS Secrets Manager and cloud-agnostic solutions like Hashicorp Vault, GCP Secrets Engine and Azure Key Vault are a few examples of secrets managers that also make an app look simple.
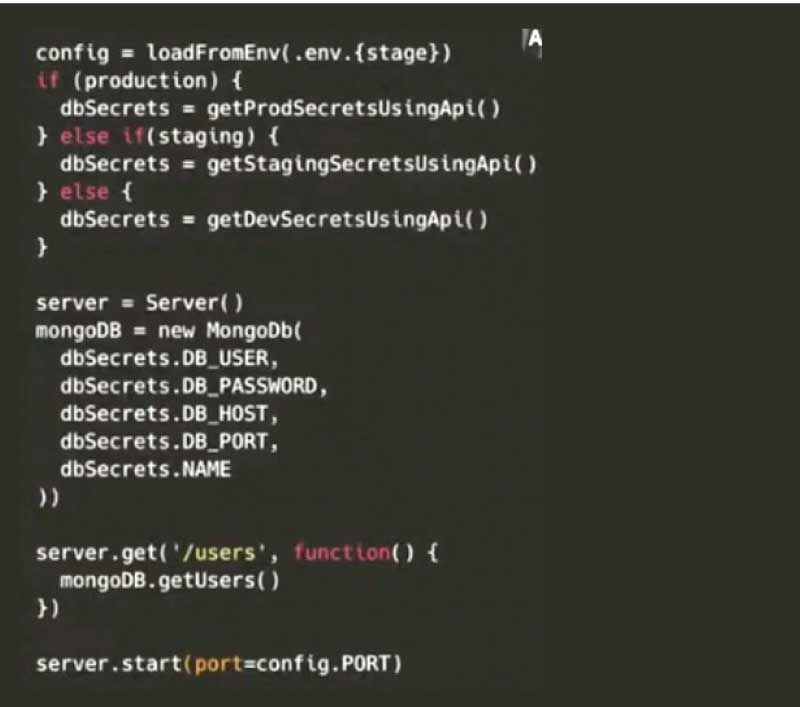
You can leave dotenv files and move only sensitive parameters to a secrets manager. The code can be changed to read these variables from the two sources.
The code will now load things first from the dotenv file and then contact secrets manager API to get the actual value of the secrets. The API may vary accordingly, since the secrets are different for staging, production or development.
The code gets the secrets inside the application, and depending on which secrets manager is being used, the corresponding library is imported. This may not be a good solution, as there can be a lot of duplication of code for every single application inside the company. Abstracting it out as a library can make the code less feasible, and adding/deleting environments dynamically can be tedious.
Managing secrets via SecretsFoundry
Since there are major issues in moving the code to fetch secrets from inside the application and integrating it with multiple secrets managers, SecretsFoundry, a cloud-agnostic solution to make secrets management simple and secure, is of help. It figures out a solution to load all the secrets, passes it back to your application in a secure way, and also works on all platforms with different secrets managers.
Your code should now have a flow from dotenv files (production, staging or development) for each of the environments and then commit to Git. You are actually not writing any of the credentials in these files, but just the path to the secrets manager. An example of code using Node.js is shown in Figure 8.
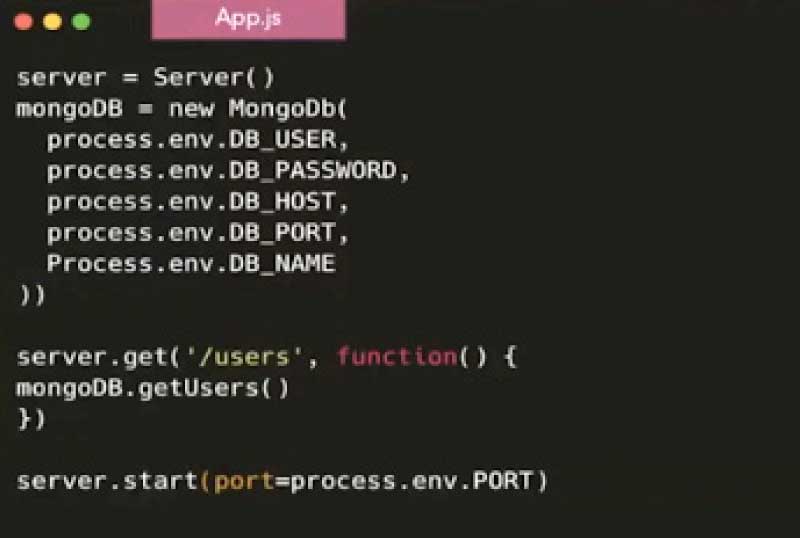
We are just accessing the process dotenv file directly without writing code to fetch any of the environment variables inside the code. However, the command to run the app needs to change.
secretsfoundry run --stage=”development” -- script “node app.js”
Behind the code, it looks at the environment variables. For example, if you see the dotenv development file, there is a database name, user name and password in plain text. It is safe in the local development environment and developers can access it using the dotenv development.local command. SecretsFoundry will read each of the variables and will put these as environment variables to run the application process. This may just be simple environment file parsing, but more critical changes happen in the production file.

DB_NAME=${aws-ssm:/production/db/name}
In the dotenv production file, the database name is written as aws-ssm, followed by the path to the secret. It tells your SecretsFoundry to fetch the value from the AWS Parameter Store with this key — production/DB/name, so as to give the actual value.
DB_USER=${aws-secrets(region=us-east-2):/prod/db/username
In the DB user, the code should be written in a way that it can be fetched from the AWS Secrets Manager. In a similar way, we integrate with different providers like HashiCorp Vault and Amazon S3, so that you can just write in the env file where the source of the credential is, and SecretsFoundry will fetch it dynamically at runtime. This way it is much safer to commit the dotenv production file to Git.
| How does SecretsFoundry work? |
| SecretsFoundry reads every variable defined in the dotenv.* file according to the stage sent by the user in the run command and loads the necessary values. Here is an example: DB_PASSWORD=${aws-ssm;/app/staging/DB_PASSWORD}
You can see that the format of defining each environment (everything under the dollar symbol) is a variable that SecretsFoundry will try to parse out and first see the provider. The AWS Parameter Store is the provider here, with /app/staging/DB_PASSWORD being the path to the secret inside it. SecretsFoundry uses AWS APIs and secrets manager APIs to get values, and then puts in the environment variable to run the code. So your code will find the value of /app/staging/DB_PASSWORD automatically in the environment variable DB_password. This way, a developer can have as many dotenv files inside your repository and use the corresponding environment file by just passing this as an argument. |
At the moment, SecretsFoundry can integrate only with AWS Parameter Store, AWS Secrets Manager, AWS S3 and HashiCorp Vault. It may soon be compatible with GCP Secrets Engine and Azure Key Vault. SecretsFoundry is currently available as an open source NPM package.

Container support
SecretsFoundry can also support containers and Kubernetes.
ENTRYPOINT [“secretsfoundry”, “run”, “--stage”, “prod”, “-s”, “node example.js”]
The developer working with the Docker file just has to change the ENTRYPOINT to secretsfoundry first and then run it, followed by the stage in which it is being run.
Then the actual script, which was being written earlier as the ENTRYPOINT, must be included (as shown in the code snippet above).
This will execute the same logic when Docker starts. You also have to provide the access credentials for AWS Secrets Manager or for Hashicorp Vault once in the deployment infrastructure. And after that, developers can themselves keep pushing code without any manual intervention needed in the development environment for sinking environment variables.
You can also think of integrating SecretsFoundry into your CI/CD pipeline. When it runs, it will print the values of all the environment variables that it can parse out.
This article is based on a talk given at OSI 2021 by Abhishek Choudhary, co-founder of Ensemble Labs (TrueFoundry)




















{kind=link}