






























































This article looks at the architectural patterns for implementing and deploying application resilience, security and containers using service mesh in microservices architecture.
Many large enterprises have begun modernisation of their applications as part of their digital transformation initiatives. They are packaging applications written in Java stack earlier into container technology, so that these can be run in hybrid multi-cloud environments. While doing so, architects and designers take a conscious decision to separate architectural concerns such as basic security (authentication and authorisation), application resiliency, traffic management and external service connectivity from the functional architecture of the modernised microservices based applications. To take care of these concerns, services are enmeshed within a service mesh. The architectural patterns that follow in this article have been harvested from some real-life implementation projects, where the service mesh is implemented by Istio and OpenShift.
Application resiliency using circuit breaker and pool ejection
The problem it solves
In distributed microservices architecture, application failures, latency spikes and other network failures have a cascading effect on the services in the call chain and hence in the overall system’s resiliency. Microservices written in different languages and deployed in different nodes within and across clusters have different response times and failure rates. Even if one service within a chain of services does not perform well, the entire availability and response time of the system is affected badly.
Pattern description and solution
This pattern has three sub-patterns, which work together. These are: circuit breaker, pool ejection, and request throttling.
Circuit breaker: Assuming the above happened in a distributed system, the solution is to implement service mesh circuit breaker (CB) and pool ejection patterns to limit the impact of such failures, latency spikes and other network irregularities. The pattern is to ‘open’ the circuit and/or eject unhealthy containers for a designated period. The CB can be at:
- Ingress point
- Between each service within the mesh
- At egress while calling an external service
Within the service mesh, envoy proxy can intercept calls and enforce a circuit breaking limit at the network level, as opposed to having it configured and coded for each application independently, thus supporting distributed circuit breaking.
Figure 1 depicts a logical view of setting up circuit breakers at the point of ingress. This is done by:
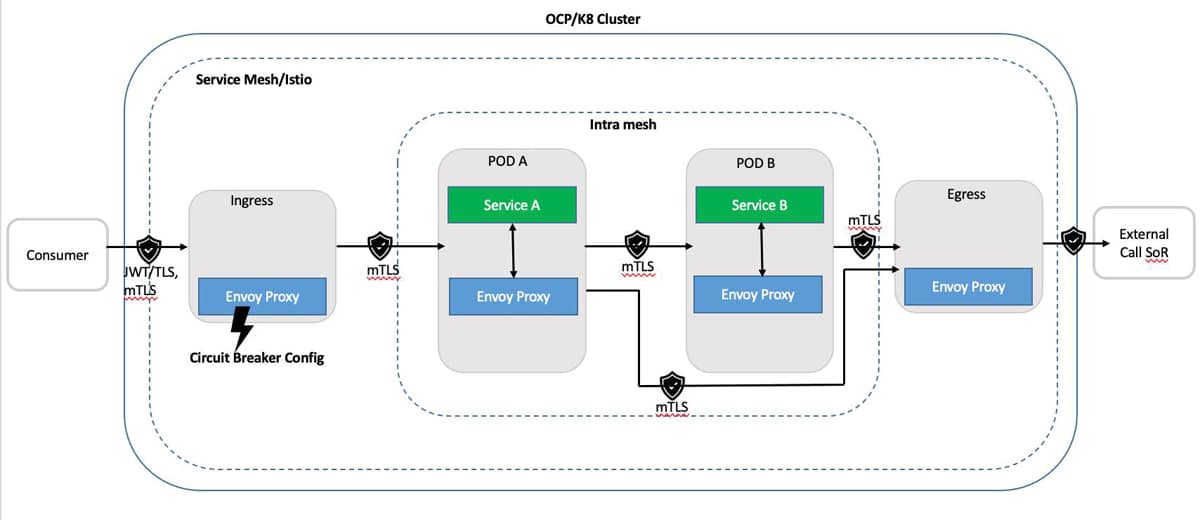
i. Configuring ingress gateway as a circuit breaker.
ii. Routing a request through ingress, detecting the behaviour of the traffic and protecting the service being called within the cluster.
iii. In case of failure, immediately returning the response to the consumer with a proper failure code.
Figure 2 depicts a logical view of setting up the circuit breaker between services inside the mesh. This is done by:
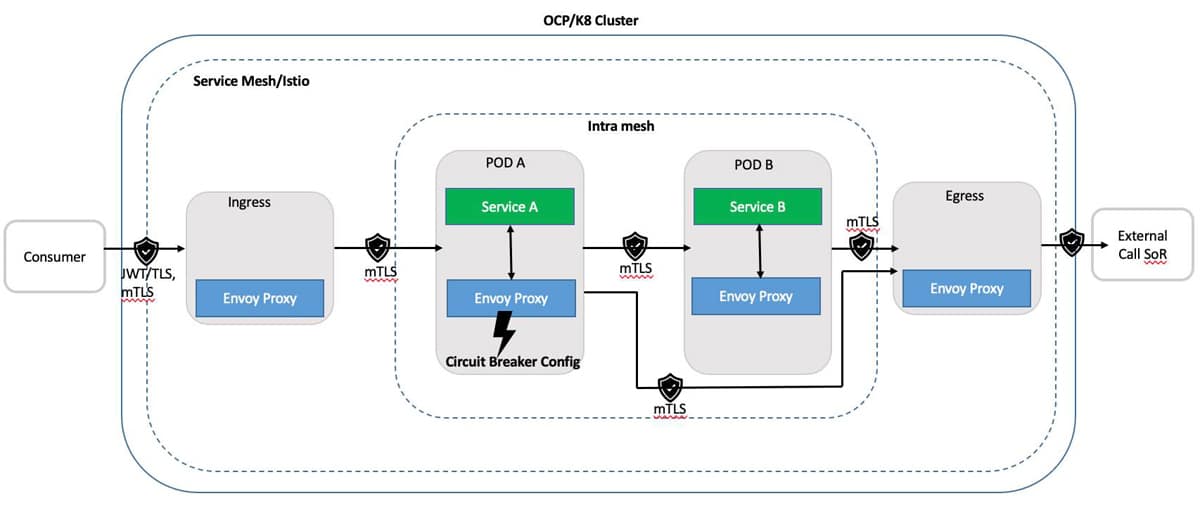
i. Configuring envoy proxy as a circuit breaker between services inside the mesh.
ii. Routing consumer requests by ingress gateway to envoy proxy in POD A.
iii. Service A calling to Service B in POD B via its envoy proxy.
iv. POD A’s envoy proxy detecting the behaviour of the traffic that is protecting the service being called within the cluster as well as the consumer.
Figure 3 depicts a logical view of setting up the circuit breaker at the point of egress. This is done by:
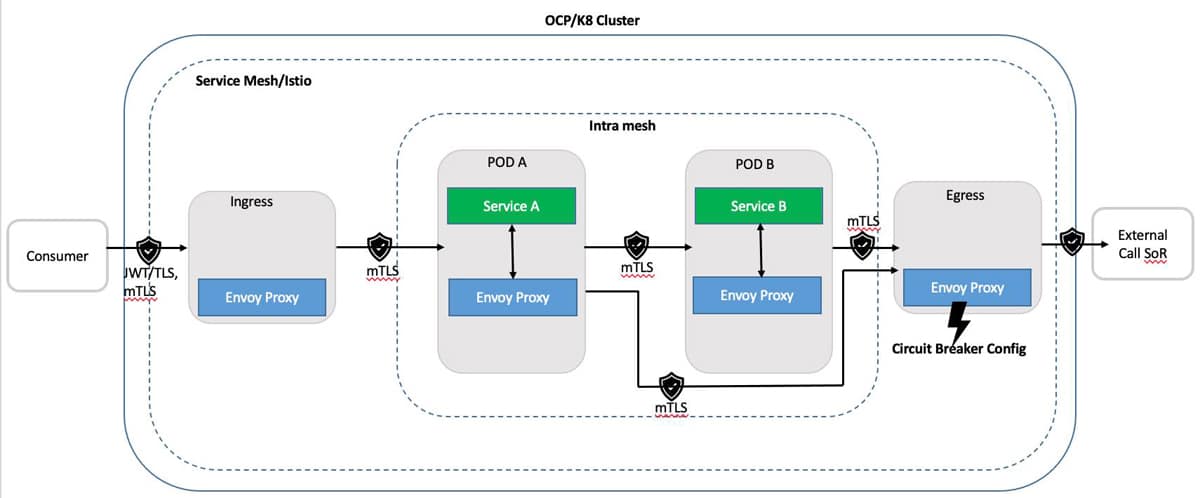
i. Configuring envoy proxy as circuit breaker at the point of egress to an external host.
ii. Routing request from consumer request through egress gateway.
iii. Detecting behaviour of the traffic and protecting the external service or system of record.
Pool ejection: In pool ejection, outlier detection prevents calls to unhealthy services and ensures any call is routed to healthy service instances. It can be used in conjunction with CB to manage the behaviour of the response to an unhealthy service.
Figure 4 depicts a logical view of setting up outlier detection using pool ejection. This is done by:
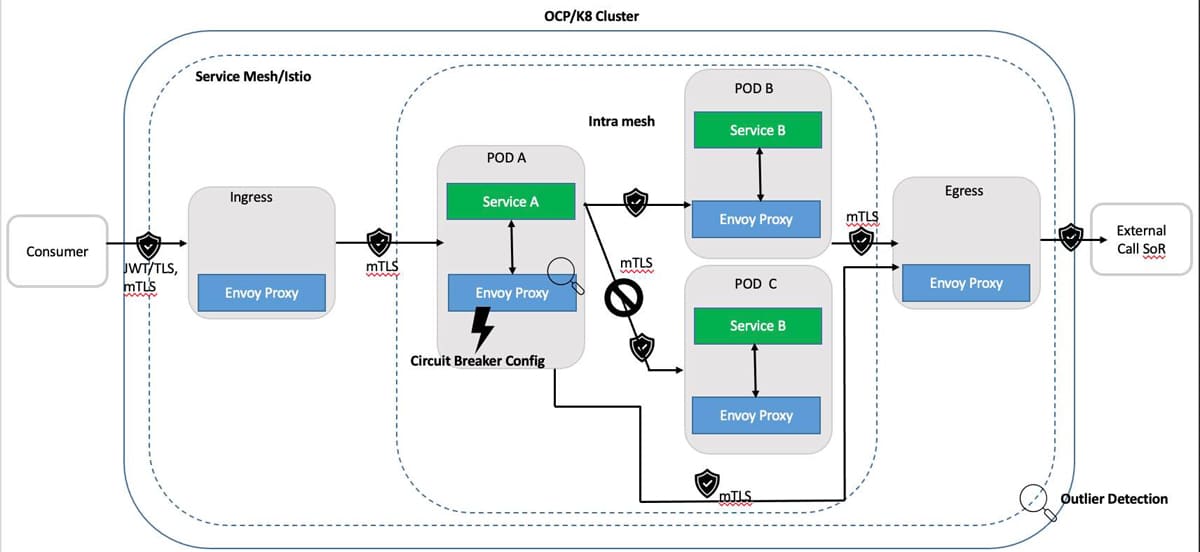
i. Configuring envoy proxy as circuit breaker with outlier detection to eject unhealthy services until such point that a minimal health percentage is detected.
ii. At this point, as a second line of defence, the circuit breaker opens if the behaviour deteriorates further due to a breach of failure rules.
Request throttling: Service mesh also provides the capability of request throttling (RT) by configuring RT at an individual client level so that no single client can consume all the available resources.
Figure 5 depicts a logical view of setting up request throttling. This is done by:
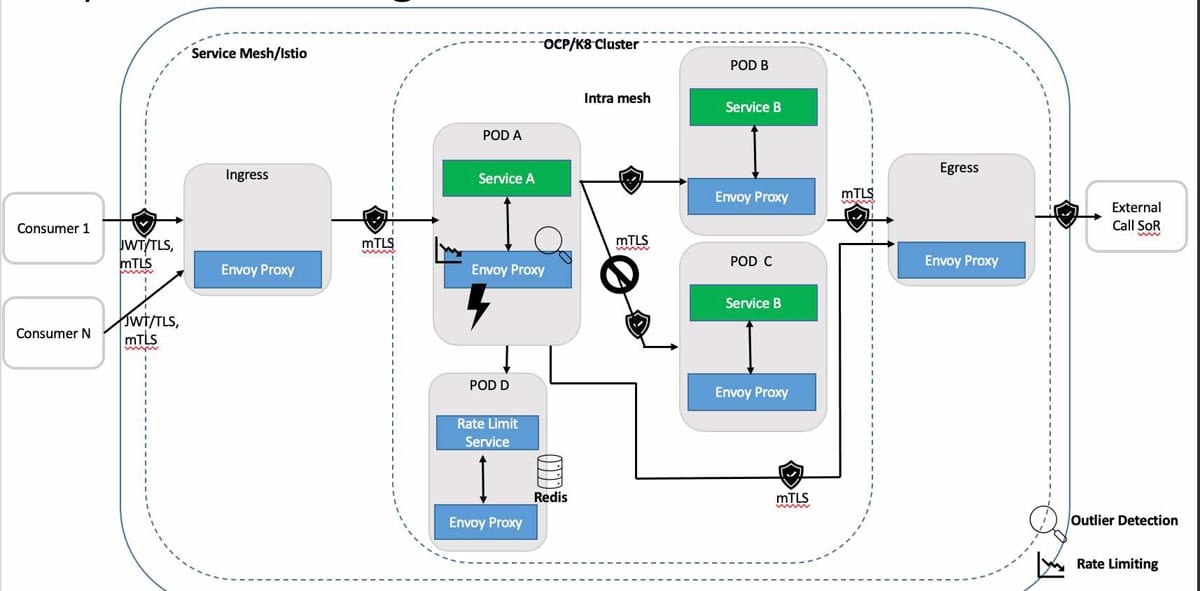
i. Setting up a global rate limiting filter for network level rate limit filter, with HTTP level rate limit filter set at the listener level.
ii. Setting up a local rate limiting filter at a more specific virtual host or route level of the service.
iii. Envoy proxy defining a rate limit service, as it does not tell by itself whether a request has to be passed through or rate limited.
Application and impact of the pattern
- This pattern is produced with reference to Istio 1.8; however, it is applicable for microservices deployment in DIY Kubernetes or OpenShift Container Platform 4.6.
- Applicability of the specific pattern described here depends on individual application design. It must consider the effects of when a circuit breaker opens based on functional and operational requirements. Consideration should be given to the applicability of a combination of resiliency capabilities to manage the flow and content of requests to a service as well as the behaviours where a problem with a service is detected.
Securing services within a service mesh
The problem it solves
In distributed microservices architecture, authentication and authorisation of the service consumers and security of payloads between services are needed. However, configuring or coding this for every service/component can become significantly complex and require much effort to manage as the number of services/components grows, since the integration touchpoints of the services also increase. Also, activities such as certificate management, key management, etc, need to be considered to properly secure services/components. The context of this pattern is adopting a zero trust approach in securing calls made via ingress or egress of the Kubernetes cluster or calls between services within the cluster. Traffic between the pods within the cluster should be treated in the same way as traffic between external components and pods in the cluster. To do all of these, the following needs to be ensured during architecture, service design and implementation:
- All message flows between the services are encrypted.
- Access control is in place to ensure only services that are able to communicate with other services are available.
- Logging and auditing telemetry data is gathered to understand typical traffic behaviour and proactively detect intrusion or retrospectively investigate what has happened.
- Zero-trust approach to protect resources without relying on the position in the network for protections.
- Security at depth to provide multiple layers to protect resources.
Pattern description and solution
Service mesh capabilities configured in the K8 cluster provide multiple capabilities to address the challenges mentioned before. Service mesh with an L7 Application Gateway ensures it acts as a policy enforcement point (PEP) providing a consistent application of authorisation policies between consumers, APIs and SoRs or external systems.
Figure 6 depicts a logical view of the capabilities implemented within service mesh to secure ingress traffic, intra mesh traffic and egress traffic.
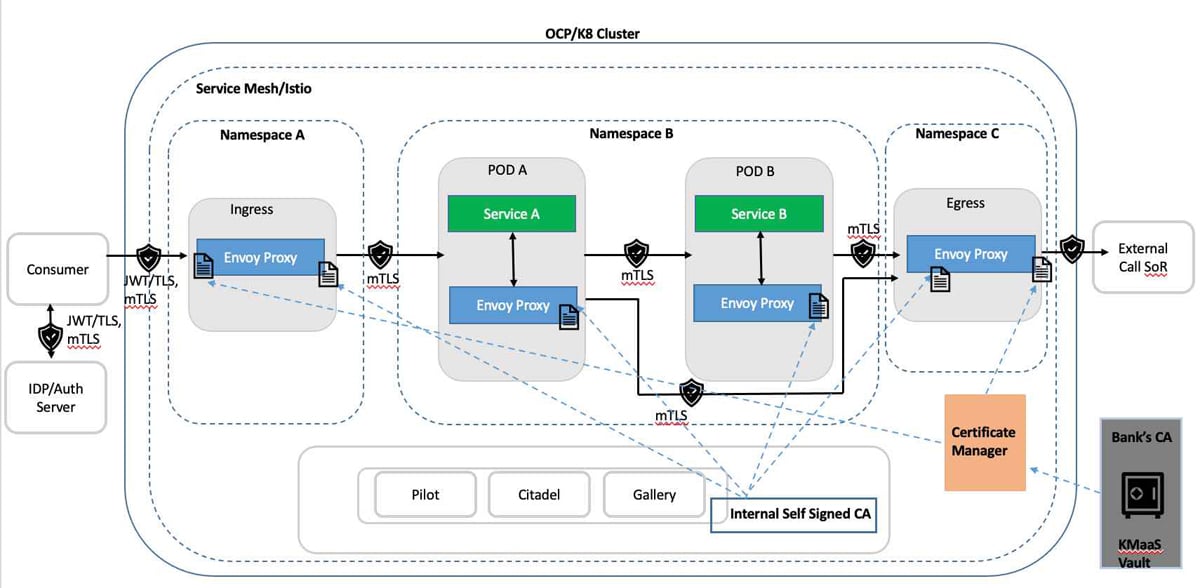
The solution and application for each of the above three security enforcement points are described briefly below with respect to the relevant security area.
Security enforcement point: Securing ingress traffic
Security area: Application authentication
Solution: Both the consumer and ingress of service mesh must use certificates signed by the designated CA of the bank/enterprise in mTLS handshake.
Application: Certificates of the ingress gateway are managed by the cert-manager of Kubernetes. It handles issuance and renewal, and manages integration to security vault or any managed service solution such as cloud based key management as service (KMaaS).
Internal certificates used for mTLS between envoy proxies should be configured for frequent rotation (e.g., six hours) to mitigate the risk of attackers obtaining service mesh certificates. Gateway certificates should be rotated in line with security standards based on KMaaS certificate’s time to live (TTL).
Security area: End user AuthN and AuthZ
Solution: The best practice is that a call from the consumer to ingress contains a JWT access token signed by a recognised authorisation server. The scope within the token will determine whether a request is authorised to access requested resources or not.
Application: Service mesh will validate the JWT’s signature based on the preconfigured public certificate in the authorised server or in the enterprise identity provider (IDP) system. It will also validate the claims in JWT and its correctness. And it will validate the scope in the access token against the authorisation policy for the target resource to decide whether access should be granted or not.
Security area: Managed ingress
Solution: All traffic to service must pass through the ingress gateway, ensuring that all pods require mTLS with certificates and identities provided by the service mesh control plane.
Application: This can be achieved by using the peer authentication policy applied in the name space of the pod, so that without mTLS pods do not accept requests in plain text traffic.
Security enforcement point: Securing intra mesh traffic
Security area: Application authentication
Solution: Pod to pod communication must be secured by mTLS configuration between sidecar proxies. A unique service account should be used for running each of the workloads in Kubernetes.
Application: Kubernetes service accounts are used to provide unique identities for each of the services of the cluster. The authentication policy discussed in the managed ingress section will ensure pods do not accept direct traffic from outside of the mesh.
Security area: Application authorisation
Solution: Use sidecar policy to control which pods can communicate with other pods. Authorisation policies should be used to explicitly define which workloads should be able to communicate with other workloads. Override default behaviour to deny all traffic to communicate with each other.
Application: Side car policy for all pods in a name space and in the name space of ingress and egress should be configured to restrict communication between services.
Security area: Managed intra-mesh
Solution: Service mesh wide mTLS along with the above mentioned policy will ensure pods can communicate with other Istio enabled pods.
Application: Enforced through mesh wide policy of ‘STRICT’ mTLS if there is no requirement to integrate with other pods that are not managed by sidecar.
Security area: Segmentation
Solution: Related services should be deployed in the same name space.
Application: In OpenShift implementation this is taken care of by creating an individual project.
Security enforcement point: Securing egress traffic
Security area: Authentication
Solution: Services within the service mesh that communicate with an external system must communicate to egress using mTLS. mTLS from service mesh should terminate at egress, and an appropriate policy should verify this before any new connection is established for the external API call. Certificates required for any specific authentication with the external system will be configured within the service mesh and used by the gateway.
Application: This needs communication to be set up with the egress gateway, with specific custom resource definition (CRD).
Security area: Authorisation
Solution: Authorisation policy should restrict access to the external system by validating the scope in access token. Claim and signature in JWT also needs to be validated to ensure the token can be used.
Application: This needs integration with enterprise identity provider (IDP).
Security area: Cross origin resource sharing (CORS)
Solution: If CORS is required, it should be implemented in service mesh instead of application code.
Application: None
Security area: Managed egress
Solution: Service mesh should be configured with service registry, which should contain the external services that should be accessed.
Application: Set mesh-wide outBoundTrafficPolicy to REGISTRY_ONLY in the mesh to ensure no service call from service mesh bypasses egress to reach any external system.
Security area: Access logging
Solution: Access to pods and gateways should be logged, along with any non-200 responses to detect attack.
Application: Envoy sidecars should be configured to record standard message information in the access log including time of request, method, protocol, upstream host, authority, and details of access token.
Impact of the pattern
Consuming application will need to provide an access token signed by an authorisation server trusted by service mesh.
- The performance impact of taking a zero trust approach and validating a token in each side car in the mesh needs to be factored in solution architecture and testing.
Service/container deployment
The problem it solves
Deployment of service containers in the production environment of any large enterprise carries the risk of code behaving differently in production environments and higher test environments. One common example is where production-specific environment variables substituted in the build pipeline do not work properly and are only discovered when the new deployment is live. This risk is coupled with the demand for a rapid deployment cadence to deliver changes to the production environment.
Pattern description and solution
Service mesh addresses this problem by simplifying traffic management and enhancing deployment strategies such as canaries, dark launches and traffic mirroring. Each provides a mechanism to mitigate risks in production changes by separating code release from cutover and a degree of testing in production. Each of the strategies is described briefly below.
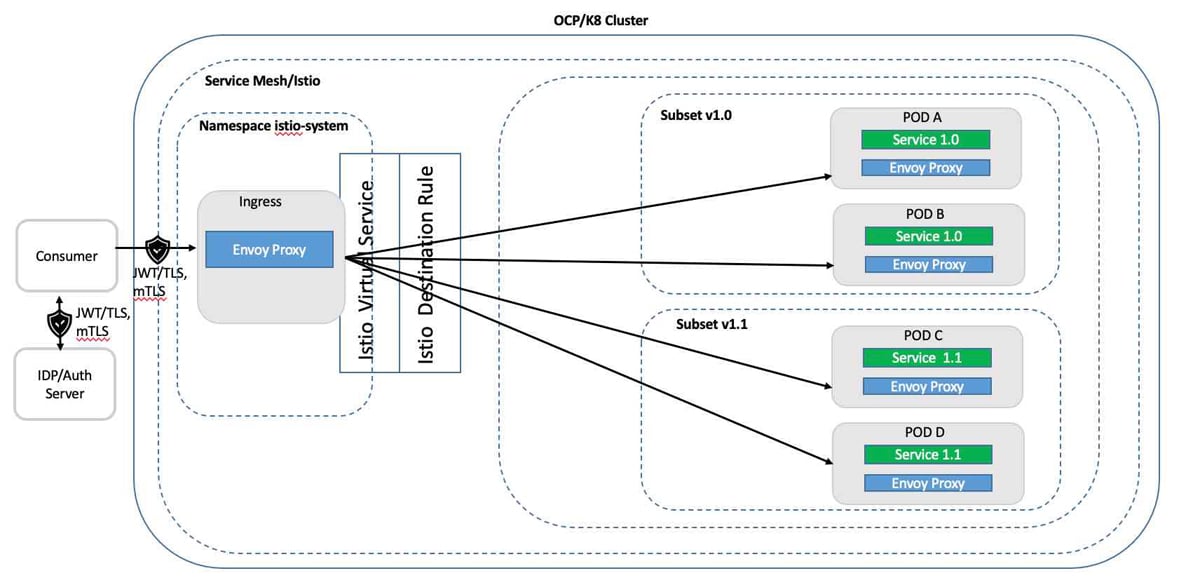
Canary deployment: This mitigates the risks associated with production changes by routing a subset of requests of the traffic to the new version while the remaining traffic is routed to the existing version. For example, for a service ViewPolicyDetails in production with version 1.0, a new minor version 1.1 is introduced, and it is decided that 10 per cent of the traffic should be routed to the new version to confirm it is behaving properly before routing all the traffic to it. As this is a minor version change, there should not be any change message schema for the consumer. By deploying the new version of the service in production and routing 10 per cent of the traffic to it through istio config, deployment of new code is separated from the cutover and validates that all is correct at each step before increasing the proportion of the traffic to the new version. Once all the traffic is routed to version 1.1, version 1.0 can be decommissioned.
Dark launches: Dark launches or A/B testing allows new versions of the service to be deployed in production separately from cutover activity. It is different from canary release in that a specific number of early adopters are moved to the new functionality to use it before it is rolled out fully. An http header is used to determine whether to route the request to the new version of the service. Istio can check the http header in the virtual service to get the name of the consuming application or some other flag, and route it to the new version. For an external consumer, an alternative approach could be to use subject alternative name (SAN) from the x.509 certificate to identify the consumer, as these details are propagated by the ingress gateway in an http header.
Traffic mirroring: Traffic mirroring or shadow launch with service mesh provides a way of deploying new services in a production environment and then sending production traffic to the new service out of band. It helps in understanding how the new service is performing with production traffic in comparison to the currently live service. As the new service is out of band, it is isolated from the existing old service and any issue or error in the new service will not impact the current service or the consumer. Care must be taken that out of band traffic does not manipulate state in live data stores. The primary use cases for this will be read-only transactions.
Figure 7 shows an application in canary deployment, dark launches and traffic mirroring where a new version v1.1 is being introduced and v1.0 is currently in use. Note that minor versions in the production environment must only be used for the transition period, and the old minor version should sunset as soon as the new minor version is stable. There are two replicas in the example of service 1.0 and 1.1 in Figure 7.
Impact of the pattern
Implementing these deployment patterns in any project should allow for more than one change deployment slot as there will be updates to the routing rules after the initial release, as well as removal of old services and pods at the end of the cycle to avoid proliferation of live services with multiple minor versions. Also, consumers should be given time for upgrading/refactoring in code, before the removal of previous versions of services from production. An alternate approach is to implement a gateway service pattern to minimise the impact on consumers.
From a technical design standpoint, a suitable regex will need to be developed and maintained for querying x509 certificate to identify the consumer, and similarly querying JWT in the http header for specific claims.



















