






























































According to Wikipedia, “Data monetization, a form of monetization, may refer to the act of generating measurable economic benefits from available data sources.” Let us briefly look at the open source tools that can help with this.
Digital transformation has led to organisations of all sizes getting too much data! This data is generated from mobiles, the web, middleware, business applications, cloud services, SaaS, backend security, monitoring, and much more, and is growing exponentially. Data stakeholders struggle to make meaning out of data lakes, ever-growing data warehouses, Big Data, etc. They develop data management strategies only to realise they have not been able to cover a good amount of new data that was generated by the time their program went live. So let us look at how to develop data monetization strategies across the organisation.
Every business’s success depends on data more than ever. However, organisations are struggling to find a workable business strategy around data. The key to successful innovation through data relies upon finding insights. Intersections of data streams, typically, are scattered, making it harder to do this. Also, in the siloed world, data is centred around its primary use application. So there is a need for flexible tools that let data reside where it is in its original format, adhering to local constraints of integrity.
Open source data frameworks and platforms
There are various open source tools that support different needs of data, including data monetization, in any given organisation, some of which are listed below.
Data lake
- The open source storage framework Delta Lake supports the construction of Lakehouse architectures using APIs for Scala, Java, Rust, Ruby, and Python as well as compute engines like Spark, PrestoDB, Flink, Trino, and Hive.
- Kylo is an enterprise-ready data lake management platform for self-service data ingesting and data preparation with integrated metadata management, governance, and security. It is inspired by Think Big’s 150+ Big Data implementation projects.
Data warehouse
- Hydra is a Postgres-based open source data warehouse with the motto ‘Data-driven decisions at every level’.
- Greenplum Database is an advanced, fully functional, open source data warehouse. It offers strong and quick analytics. A sophisticated cost based query optimiser powers this database, which is specifically designed for Big Data analytics on massive data volumes.
Data mart
- PostgreSQL, commonly referred to as Postgres, is a relational database management system that is open source, and places a strong emphasis on flexibility and SQL compliance.
- One of the most well-known open source relational databases is MariaDB Server. Performance, stability, and openness are its guiding principles, and the MariaDB Foundation guarantees that contributions will be accepted on the basis of their technical quality.
Master Data Management (MDM)
- AtroCore is free open source MDM software offered under the GPLv3 license. It is a software ecosystem created for the quick development of ERP-like and responsive web-based business apps. It is a superb tool for quick and cost-effective application development because of its configurable options and strong out-of-the-box capability.
- Pimcore enables the storing of master data, clients, goods, and more in one place. The Pimcore MDM tool has the distinctive quality of not being appropriate for small-sized businesses. It promises continuous data quality improvement and a data quality strategy.
Data analytics
- KNIME Analytics Platform is a free and open source program used for data science. It makes building data science workflows and reusable components accessible to everyone.
- RStudio is now Posit, and its goal remains the same. It wants to improve data science by making it more transparent, logical, approachable, and collaborative.
-
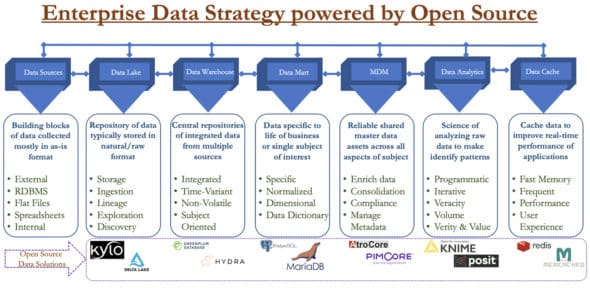
Figure 1: Enterprise data strategy powered by open source
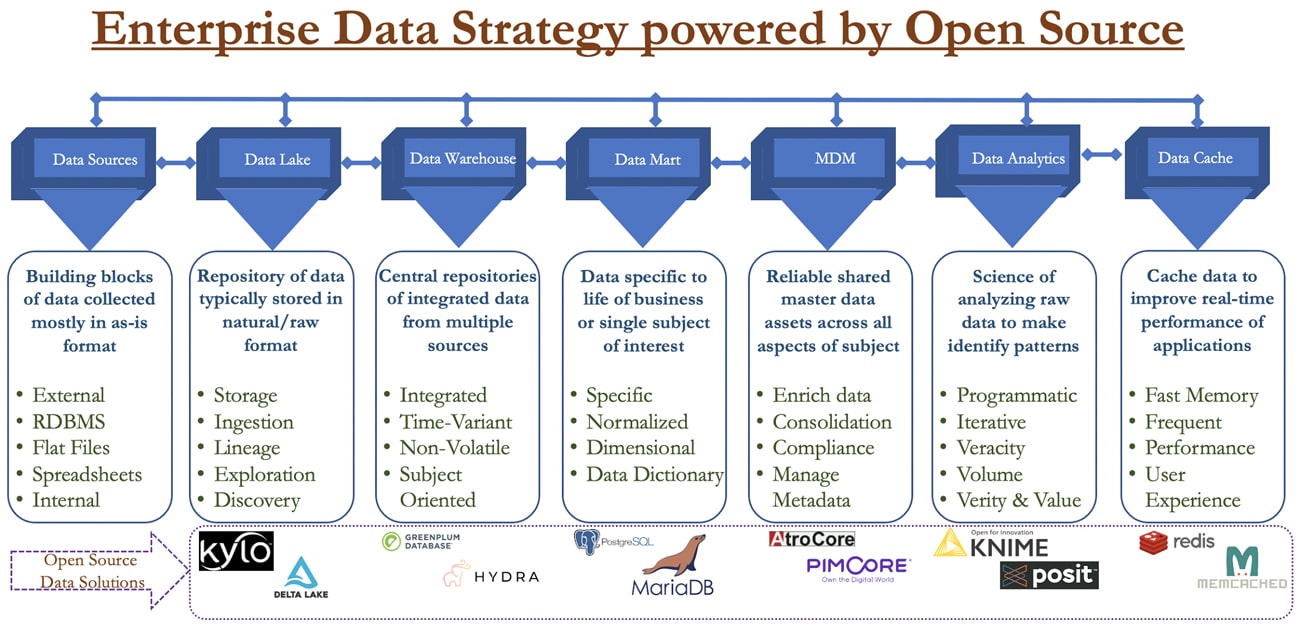
Data cache
- Memcached is a distributed memory object caching technology with great performance that was initially created to speed up dynamic web applications by reducing database load. It gives you the ability to transfer memory from parts of your system where you have more memory than you require, to sections where you have less memory than you require.
- bal;Redis is a distributed, in-memory, key-value database, cache, and message broker with optional durability that is used as an in-memory data structure store. Various abstract data structures, including strings, lists, maps, sets, sorted sets, HyperLogLogs, bitmaps, streams, and spatial indices, are supported by Redis.
In a world that’s increasingly data-rich, we need to enable the evolution of technology and culture in parallel, to discover new insights that guide business strategy, ignite innovation, and redefine how organisations achieve success.




















{kind=link}