





























































Specialised language models score over large language models in various ways. What’s more, there are a range of open source solutions you can choose from to build a reliable model.
A large language model (LLM) has millions of parameters whereas a small language model has significantly fewer parameters, uses less resources and is optimised for a specific domain. The specialised language model (SLM) can be small or large in model size but focuses on specific fields like law, healthcare, and so on.
Creating a specialised language model using multiple LLM sources
The process of developing an SLM involves harnessing the strengths of multiple LLMs to filter data effectively. This requires several steps, which are outlined below.
Data collection
The first step is to gather a diverse set of data from various sources, including domain-specific databases, scientific journals, articles, and generic data repositories. The goal is to assemble a comprehensive dataset that encompasses both specialised and general knowledge.
Data preprocessing
Data preprocessing is essential for cleaning and organising the collected data. This step involves removing duplicates, irrelevant information, and noise. Techniques such as tokenization, stemming, and lemmatization are employed to standardise the text.
Data filtering
To create an effective SLM, it is crucial to filter out domain-specific data from generic information. This can be achieved by leveraging multiple LLMs, each trained on different datasets. These models can be used to classify and segregate data based on their relevance and context.
Model training
Once the data is filtered, the next step is to train the SLM. This involves fine-tuning the selected LLMs on the domain-specific dataset. Techniques such as transfer learning and supervised learning are employed to enhance the model’s performance.
Model integration
The final step is to integrate the trained SLM with existing systems. This includes deploying the model on cloud platforms, setting up APIs for access, and ensuring seamless integration with other applications.
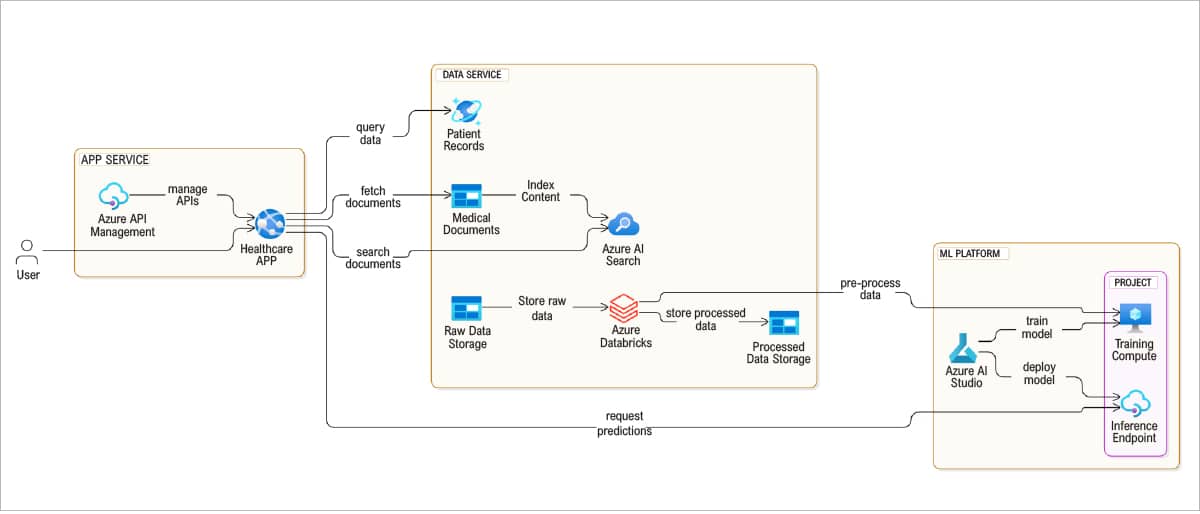
Microsoft Azure’s native services for building an SLM
Microsoft Azure provides a comprehensive suite of services that can be utilised to build and deploy an SLM.
Azure Blob Storage
Azure Blob Storage is used to store the raw and processed data. It provides scalable and secure storage for large datasets.
Azure Databricks
Azure Databricks is an analytics platform that facilitates data preprocessing, cleaning, and transformation. It integrates seamlessly with other Azure services and supports various data processing frameworks.
Azure Machine Learning
Azure Machine Learning is used to train and fine-tune the SLM. It provides a range of tools and libraries for model training, validation, and deployment.
Azure Cognitive Services
Azure Cognitive Services offers pre-trained LLMs that can be leveraged for data filtering and classification. These services include text analytics, language understanding (LUIS), and custom vision.
Azure API Management
Azure API Management is used to manage and deploy APIs for accessing the SLM. It provides security, scalability, and monitoring capabilities.
Real-time use cases in healthcare
The healthcare sector stands to benefit significantly from the implementation of SLMs. Some real-time use cases include:
Medical diagnosis
An SLM can analyse patient records, lab results, and medical literature to assist doctors in diagnosing complex conditions. For instance, it can help identify rare diseases by comparing symptoms with documented cases and suggesting possible diagnoses that may not be immediately obvious.
Drug discovery
Pharmaceutical companies can utilise SLMs to sift through vast amounts of scientific research, patents, and clinical trial data to identify potential drug candidates. By analysing patterns and correlations, the model can suggest novel compounds or repurpose existing drugs for new therapeutic uses.
Patient engagement
An SLM can enhance patient engagement by providing personalised health information and recommendations. For example, a virtual health assistant powered by the SLM can generate tailored advice based on a patient’s medical history, lifestyle, and preferences, improving adherence to treatment plans.
Clinical research
Researchers can use SLMs to extract relevant information from a multitude of research papers and clinical trial reports. This can facilitate meta-analyses, identify gaps in current knowledge, and highlight potential areas for future studies, thus accelerating the pace of medical research.
Benefits of using specialised language models
Specialised language models offer distinct advantages over general LLMs by focusing explicitly on domain-specific knowledge, terminology, and context. First, SLMs provide higher accuracy and relevance within their targeted fields. Since they are trained on specialised datasets, they understand nuanced terminologies and industry-specific jargon far better than general-purpose LLMs, significantly reducing the likelihood of misinterpretation or irrelevant responses.
Second, SLMs are more efficient in terms of computational resources. Because they are tailored to specific tasks or domains, they typically require fewer parameters and less computational power, making them more cost-effective and faster to deploy. This efficiency is particularly beneficial for organisations with limited resources or those requiring real-time responses.
Third, the precision of SLMs enhances user trust and reliability. Users interacting with specialised models experience consistent, accurate, and contextually appropriate outputs, crucial in sectors such as healthcare, law, finance, or engineering, where inaccuracies can lead to critical consequences.
Lastly, specialised models facilitate easier fine-tuning and updating. Organisations can quickly adapt these models to evolving industry standards or emerging terminologies, maintaining their relevance and accuracy over time. In contrast, general LLMs require extensive retraining and resources to achieve similar domain-specific adaptability.
Overall, specialised language models outperform general LLMs in domain accuracy, computational efficiency, reliability, and adaptability, making them highly beneficial for targeted applications where precision and contextual understanding are paramount.
Open source solutions for developing SLMs
A variety of open source solutions are available for developing a specialised language model. These solutions provide frameworks, tools, and pre-trained models that can be fine-tuned or customised for specific domains, industries, or tasks.
Hugging Face Transformers
Overview: Hugging Face is one of the most popular libraries for working with transformer-based models like BERT, GPT, RoBERTa, and others.
Key features
- Pre-trained models for a variety of tasks (e.g., text classification, summarisation, question answering).
- Fine-tuning capabilities for domain-specific tasks.
- Integration with PyTorch and TensorFlow.
- Tokenizers optimised for various languages and tasks.
Use case: Fine-tuning a general-purpose model (e.g., GPT-2, BERT) for specific applications like legal text analysis, financial data processing, or medical language understanding.
Advantages
- Large community support and active development.
- Easy-to-use APIs for training, fine-tuning, and inference.
Example: Fine-tune BERT on a medical corpus (e.g., PubMed articles) to create a specialised model for medical text understanding.
OpenAI GPT models (open source variants)
Overview: While OpenAI’s GPT-3 is proprietary, there are open source implementations of GPT-like models, such as GPT-2 and GPT-Neo.
Key features
- Pre-trained transformer-based models for text generation.
- Ability to fine-tune on domain-specific datasets.
- Scalable to large datasets and tasks.
Open source alternatives
- GPT-2: Released by OpenAI, available for fine-tuning.
- GPT-Neo/GPT-J: Open source alternatives to GPT-3 by EleutherAI.
Use case: Training a GPT-like model for creative writing, customer support automation, or domain-specific conversational AI.
Advantages
- Open source variants provide flexibility and control over the model.
- Large-scale pre-trained models available for adaptation.
Rasa
Overview: Rasa is an open source framework specifically designed for building conversational AI and chatbots.
Key features
- Natural language understanding (NLU) for intent recognition and entity extraction.
- Dialogue management for creating conversational flows.
- Customisable pipelines for language model integration.
Use case: Building a chatbot for customer service in a specific industry (e.g., healthcare, e-commerce).
Advantages
- Tailored for conversational AI applications.
- Easy integration with domain-specific datasets.
- Active community and enterprise support.
SpaCy
Overview: SpaCy is a fast and efficient library for natural language processing (NLP) with support for training custom pipelines.
Key features
- Pre-trained models for multiple languages.
- Tools for custom tokenization, named entity recognition (NER), and dependency parsing.
- Integration with transformer models via the spacy-transformers package.
Use case: Developing a lightweight language model for tasks like domain-specific NER or text categorisation.
Advantages
- Lightweight and efficient for production use.
- Easy to train and deploy custom pipelines.
AllenNLP
Overview: AllenNLP is a research-focused NLP library built on PyTorch, designed for experimenting with and building custom NLP models.
Key features
- Modular design for building and training custom models.
- Pre-built components for common NLP tasks (e.g., text classification, sequence tagging).
- Integration with transformer-based models.
Use case: Prototyping and training custom NLP models for academic research or specialised tasks.
Advantages
- Research-oriented with support for custom architectures.
- Strong focus on explainability and visualisation.
Fairseq
Overview: Fairseq is a sequence-to-sequence modelling toolkit by Facebook AI Research, supporting tasks like machine translation and text generation.
Key features
- Support for transformer and other sequence-to-sequence architectures.
- Customisable training pipelines.
- Pre-trained models for translation, summarisation, and more.
Use case: Developing a specialised translation model for low-resource languages or domain-specific text generation.
Advantages
- High flexibility for sequence-to-sequence tasks.
- Scalable for large datasets and distributed training.
OpenNMT
Overview: OpenNMT is an open source toolkit for training neural machine translation models, but it can also be adapted for other NLP tasks.
Key features
- Support for training custom models from scratch.
- Tools for preprocessing and tokenizing text data.
- Flexible architecture for incorporating domain-specific data.
Use case: Training a translation model for legal or technical documents.
Advantages
- Highly customisable for domain-specific tasks.
- Active support for multilingual applications.
T5 (Text-to-Text Transfer Transformer)
Overview: T5 is a transformer model by Google that treats all NLP tasks as text-to-text problems.
Key features
- Unified framework for tasks like classification, translation, and summarization.
- Pre-trained models available for fine-tuning.
- Open source implementation via Hugging Face and TensorFlow.
Use case: Training a model for domain-specific summarization or question answering.
Advantages
- Versatile framework for multiple NLP tasks.
- Easy to fine-tune for specialised use cases.
FastText
Overview: FastText is a lightweight library by Facebook for text classification and word representation.
Key features
- Efficient training of word embeddings.
- Support for supervised and unsupervised learning.
- Works well with small datasets.
Use case: Building a domain-specific text classifier or embedding model for real-time applications.
Advantages
- Extremely fast and efficient.
- Suitable for resource-constrained environments.
Cohere (open source support)
Overview: Cohere offers APIs for language model training and inference, with open source support for model customization.
Key features
- Pre-trained models for text generation and classification.
- Fine-tuning for domain-specific applications.
- Integration with open source NLP tools.
Use case: Creating a specialised language model for marketing or creative content generation.
Advantages
- Easy-to-use APIs for rapid experimentation.
- Focus on practical applications.
SentenceTransformers
Overview: A library for building and fine-tuning sentence embeddings using transformer models.
Key features
- Pre-trained models for generating semantic embeddings.
- Fine-tuning for domain-specific similarity tasks.
- Integration with Hugging Face models.
Use case: Developing a semantic search engine or recommendation system for a specific domain.
Advantages
- Optimised for embedding-based tasks.
- Lightweight and efficient for real-world deployment.
BLOOM
Overview: BLOOM is an open source multilingual language model developed by BigScience.
Key features
- Large-scale transformer model trained on diverse datasets.
- Support for multiple languages and domains.
- Fine-tuning capabilities for specialised tasks.
Use case: Adapting the model for low-resource languages or multilingual tasks.
Advantages
- Open source alternative to proprietary large models.
- Community-driven development.
Steps to develop a specialised language model
Define the use case
Identify the specific task (e.g., classification, summarization, translation); understand the domain and collect relevant data.
Select the framework
Choose an open source solution based on the task complexity and resources available.
Data collection and preprocessing
Gather domain-specific data for training, and clean and preprocess the data (e.g., tokenization, normalization).
Fine-tuning or training
Use pre-trained models and fine-tune them on your dataset. Train from scratch if necessary, using frameworks like Fairseq or OpenNMT.
Evaluation and testing
Evaluate the model using domain-specific metrics, and iterate and improve based on feedback.
Deployment
Deploy the model using frameworks like FastAPI, Flask, or TensorFlow Serving.
Developing reliable AI using SLM architecture
Reliable AI refers to artificial intelligence systems that are robust, trustworthy, and capable of delivering consistent and accurate results in a variety of scenarios, even in the face of challenges like data biases, adversarial inputs, or domain-specific complexities. When it comes to specialised language models (SLMs), reliability becomes even more critical because these models are often tailored to specific industries or use cases, where errors or inconsistencies can have significant consequences (e.g., healthcare, finance, legal domains).
To ensure reliability in SLM-based systems, the following factors should be addressed.
Accuracy and robustness
The model must consistently perform well across its intended tasks, even when faced with noisy, incomplete, or adversarial data. For SLMs, this means fine-tuning on high-quality, domain-specific datasets while ensuring generalisation to unseen scenarios.
Fairness and bias mitigation
Language models often inherit biases from training data. In SLMs, biases can be amplified if the domain-specific data is skewed. Reliable SLMs must mitigate biases to ensure fairness, especially in sensitive applications like hiring, legal judgments, or medical diagnostics.
Explainability and interpretability
Users and stakeholders must understand how and why the SLM makes certain predictions or generates specific outputs. Explainability is crucial for building trust, especially in regulated industries.
Scalability and adaptability
Reliable SLMs should scale to handle large datasets or adapt to new domains with minimal retraining. They must also remain robust in multilingual or multimodal contexts.
Security and privacy
SLMs must be resistant to adversarial attacks and data poisoning. Privacy-preserving techniques (e.g., differential privacy, federated learning) should be incorporated to protect sensitive data.
SLM architecture principles for reliable AI
SLMs are typically built on transformer-based architectures (e.g., BERT, GPT, T5) that are fine-tuned or trained from scratch for domain-specific tasks. Given below are a few architecture principles and enhancements for ensuring their reliability.
Pre-trained foundation models
Use robust, well-tested pre-trained models such as BERT, GPT, or BLOOM as the foundation. Pre-trained models provide a strong baseline. They are trained on diverse datasets, which improves generalisation.
Domain-specific fine-tuning
Fine-tune the pre-trained model on curated, high-quality domain-specific datasets. As an example, you can fine-tune BERT on legal documents to create ‘LegalBERT’ or on medical texts to create ‘BioBERT’.
Techniques for reliability
Use transfer learning to leverage knowledge from general-purpose models. Apply data augmentation to increase dataset diversity and robustness.
Modular architectures
Break down the SLM into smaller, modular components for specific tasks (e.g., entity recognition, sentiment analysis, summarization). Modular architectures improve interpretability and allow for easier debugging.
Multi-task learning
Train the SLM on multiple related tasks simultaneously (e.g., classification + summarization + question answering). Multi-task learning helps the model generalise better and reduces overfitting on a single task.
Reinforcement Learning with Human Feedback (RLHF)
Incorporate human feedback into the training loop to align the model’s behaviour with user expectations. For example, OpenAI’s fine-tuning of GPT models using RLHF improves reliability and alignment.
Knowledge injection
Inject domain-specific knowledge (e.g., medical guidelines, legal rules) into the SLM to improve reliability in specialised tasks. This can be done in two ways. Use external knowledge graphs to enhance the model’s reasoning abilities, and design prompts that guide the model towards reliable outputs.
Strategies for building reliable SLMs
High-quality data curation
Use clean, diverse, and representative datasets for training and fine-tuning. Remove noise and biases during preprocessing.
Domain-specific data
Collect data that reflects the specific domain (e.g., legal, medical, financial). Use synthetic data generation to augment limited datasets.
Robust evaluation metrics
Use task-specific metrics (e.g., F1 score, BLEU score) to evaluate performance. Evaluate robustness using adversarial testing and out-of-distribution data.
Cross-domain testing
Test the SLM on datasets from related domains to assess generalisation.
Explainability tools
Implement explainability techniques to provide insights into model decisions.
- SHAP (SHapley Additive exPlanations): Explain feature importance.
- Attention visualisations: Show which parts of the input the model focuses on.
- Counterfactual analysis: Explores how small input changes affect the output.
Bias detection
Use tools like AIF360 (AI Fairness 360) to detect biases in the training data and model outputs.
Bias mitigation techniques
Reweight training data to balance underrepresented groups. Use adversarial training to reduce bias.
Privacy-preserving techniques
Implement differential privacy to ensure that individual data points cannot be reverse-engineered. Use federated learning to train models on decentralised data without sharing sensitive information.
Security measures
Protect against adversarial attacks by training on adversarial examples. Monitor for data poisoning during training.
Continuous monitoring and updates
Deploy monitoring systems to track the model’s performance in real-world scenarios. Continuously update the model with new data to adapt to changing trends or requirements.
Challenges in ensuring reliable AI with SLMs
Data limitations
Lack of high-quality, domain-specific data can limit the model’s reliability. Over-reliance on biased or incomplete datasets can lead to errors.
Overfitting to domain-specific data
Fine-tuning on small datasets can cause the model to overfit and lose generalisation.
Explainability vs complexity
Transformer-based models are inherently complex, making it difficult to explain their decisions.
Scalability
Training large SLMs requires significant computational resources, which may not be feasible for all organisations.
Bias amplification
SLMs can amplify biases present in domain-specific data, leading to unfair or unreliable outcomes.
Creating a specialised language model using multiple LLM sources involves meticulous data collection, preprocessing, filtering, and model training. Microsoft Azure’s native services can be leveraged to build a robust and scalable architecture for deploying these models. However, ensuring data quality and reliability is crucial for building an effective SLM.


















{kind=link}