





























































This short tutorial will teach you how to create your own Word2Vec model from a small corpus using the Gensim library.
Large language models (LLMs) like ChatGPT and Gemini are being used extensively today in the world of generative AI. We must therefore understand and learn the important concepts of natural language processing (NLP), which is the base for GenAI. One such concept is ‘word embeddings’. While training a machine learning model, you need to give the inputs and outputs as numbers to the machine, because that is what it understands. Your machine does not understand text or image data directly. For any application of NLP, you must convert your text into meaningful numbers, which are called embeddings.
One such method to convert text data into numbers or numerical data is Word2Vec. It literally means converting words to vectors, which are arrays/sets of numbers that represent a given word. A few other methods were used earlier to convert words to numbers (like one-hot encoding and Bag of Words). Word2Vec is better because the earlier methods could not capture the meaning of the order of text. Text is sequential data in which the order of words is important. Not capturing this information becomes a problem in many use cases.
Word2Vec models are trained on large corpuses to make them more useful. Once trained, these models can be used for a multitude of use cases like predicting the next word in a piece of text, detecting synonyms or predicting how close a word is to another given word and, of course, to convert text into embeddings. This technique was developed by researchers at Google and was published in 2013. Word2Vec models are typically artificial neural network models, which create vectors that have dimensions in the hundreds. Each word in the corpus is assigned a unique vector. This is done using two methods — CBOW or Continuous Bag of Words and Skipgram.
Let’s now learn how to create your own Word2Vec model from a small corpus. We are going to use the Gensim library for this purpose. You can install this on your Jupyter Notebook using the following command as shown in Figure 1.
!pip install gensim
We now need to create a corpus. I have created a corpus of some random sentences as shown below:
corpus = [ “Jishnu is amazing”, “Jishnu loves machine learning”, “Deep learning is beautiful”, “Word2Vec is a great way of creating word embeddings”, “Gensim makes NLP easy”, “Deep learning is a part of machine learning.” ]
The next step is the tokenisation process. We need to tokenise the corpus that we have. Here we are doing word level tokenisation, i.e., we are splitting the corpus into words. We can do this using the following code as shown in Figure 2.
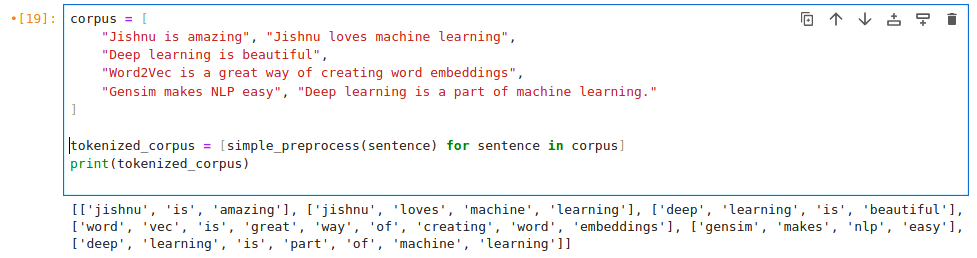
from gensim.utils import simple_preprocess tokenized_corpus = [simple_preprocess(sentence) for sentence in corpus] print(tokenized_corpus)
Now you need to train your Word2Vec model. This can be done using the Gensim library that we installed and the functions in it, as shown in the code below.
from gensim.models import Word2Vec model = Word2Vec(sentences=tokenized_corpus, vector_size=20, window=4, min_count=1, workers=4)
As we discussed, any word can be represented by a vector in our model. We can do that using the following lines of code as shown in Figure 3.

vector = model.wv[‘learning’] print(vector) The figure shows how we can represent the word ‘learning’.
We can also get the words that are closest to a given word in the trained vector space. Let us get the top three words similar to the word ‘machine’. We can do this using the following code, as shown in Figure 4.

similar_words = model.wv.most_similar(‘machine’, topn=3) print(similar_words)
This is it! You can create your Word2Vec model now!
Now let us look at one of the most popular Word2Vec models, which is the ‘GoogleNews-vectors-negative300.bin’ model. This is a model that has been trained on a huge dataset. It was trained on the Google News corpus, which contains billions of words. This model can give vector representations of most words we use. You can download it from https://huggingface.co/NathaNn1111/word2vec-google-news-negative-300-bin.
Once downloaded, it can be used for a wide variety of tasks such as text classification, machine translation, and more. Let us see how we can use this model to get the vector representation of the word ‘learning’ as shown in Figure 5.
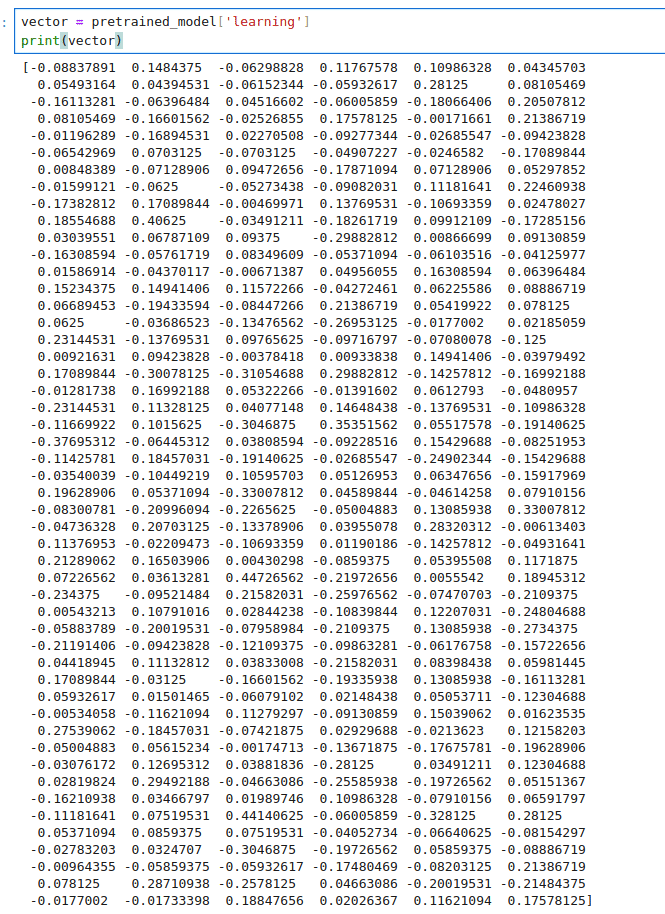
from gensim.models import KeyedVectors model_path = “/home/jmittap/Downloads/GoogleNews-vectors-negative300.bin” pretrained_model = KeyedVectors.load_word2vec_format(model_path, binary=True) vector = pretrained_model[‘learning’] print(vector)
This model is proof that Word2Vec models capture the meaning in text. The most popular example used for showing this is that the following:
→ The vec(King) – vec(Man) + vec(Women) →
…gives the vector embedding of the word Queen! How cool is that! This can be done as shown in Figure 6. This proves that the meaning of things like ‘Royalty’ has been captured by this model!

You can now try and use this word embedding technique in different NLP and ML projects!
















