

One of the aims of responsible AI is to make sure no injustice creeps into the data that large language models are based on. Fairlearn is an open source tool that can help with this.
The amount of data that is being used to train large language models today, which have billions of parameters, causes serious privacy and other concerns. Responsible AI and AI governance have become very important and relevant today. The fundamentals of responsible AI include transparency, bias, fairness, privacy, and accountability. Here, we will primarily focus on fairness.
Fairness is basically the practice of developing or using algorithms and models in such a way that they provide decisions that are equitable, unbiased and non-discriminatory to different demographic groups.
Fairlearn is a tool that helps us ensure and improve fairness while building a model. It is an open source Python toolkit, initially developed by Microsoft, and is designed to measure and mitigate unfairness in ML models. It provides easy-to-use tools for evaluating fairness and adjusting models to reduce bias.
Ensuring fairness in a model requires two steps. The first is to measure fairness and the second is to mitigate the unfairness. Fairlearn helps us with both! To measure fairness, it first identifies disparities in metrics like accuracy or false-positive rate across sensitive groups (e.g., gender, race). Then, to mitigate the unfairness it modifies models or predictions to reduce bias while balancing performance.
Fairlearn supports three approaches to fairness. The first is during pre-processing, where it helps adjust the data before training to remove bias. During processing, it helps train the models with fairness constraints, and in post-processing, it helps adjust the predictions after training.
Let us now look at a coding example that will help you understand this better. You can open any code editor you like — I will be using Google Colab. You can open a Jupyter Notebook through the terminal, or on VSCode, or anywhere that you feel comfortable.
Open Google Colab using the link https://colab.research.google.com.
Once your Jupyter Notebook is up and running, you can install Fairlearn using the following command:
pip install fairlearn
We will try this example with a sample random dataset. For this, import all the required libraries in a new cell as shown below:
import numpy as np import pandas as pd from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, confusion_matrix from fairlearn.metrics import MetricFrame, false_positive_rate from fairlearn.reductions import ExponentiatedGradient, DemographicParity
We are importing NumPy and Pandas to generate and use the dataset, and importing logistic regression from sklearn to build our model. We first fix the random seed so that the results are reproducible. We will then generate a simple feature set with two numeric features and 100 rows. This is purely synthetic data, just as an example for us to use in this code. Next, we create a binary target variable simulating a label. We can do this using the following code:
np.random.seed(42)
X = pd.DataFrame({
“feature1”: np.random.randn(100),
“feature2”: np.random.randn(100)
})
y = np.random.choice([0, 1], size=100)
The following code represents sensitive attributes, i.e., the columns that we’ll use to evaluate fairness. They would usually be features like gender, race, etc, that may cause bias and unfairness.
sensitive_feature = np.random.choice([“GroupA”, “GroupB”], size=100)
We then split the features, labels, and sensitive attributes into training and test sets, keeping 30% of the data aside for evaluation using the following code:
X_train, X_test, y_train, y_test, s_train, s_test = train_test_split( X, y, sensitive_feature, test_size=0.3 )
We start with a plain logistic regression model. At this point, there is nothing fairness-aware about it — it’s just optimising for prediction accuracy. The model has been trained using the training features and labels, learning a set of coefficients that best separate the two classes.
clf = LogisticRegression() clf.fit(X_train, y_train) y_pred = clf.predict(X_test)
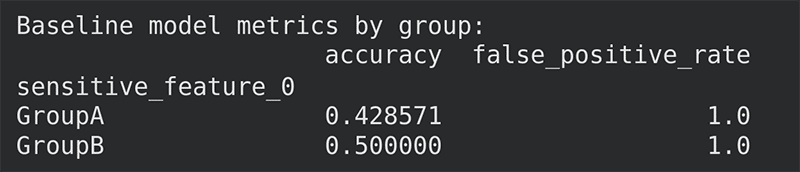
The next step is where fairness comes into play. MetricFrame calculates metrics separately for each sensitive group, allowing us to see whether performance differs between GroupA and GroupB. In addition to accuracy, we include false positive rate, which is often critical in fairness discussions. We then get the metrics as shown in Figure 1.
metrics = MetricFrame(
metrics={“accuracy”: accuracy_score, “false_positive_rate”: false_positive_rate},
y_true=y_test,
y_pred=y_pred,
sensitive_features=s_test
)
print(“Baseline model metrics by group:”)
print(metrics.by_group)
Next, we set up a fairness-aware version of logistic regression using Fairlearn’s Exponentiated Gradient algorithm. By specifying demographic parity as the constraint, we’re asking the model to balance positive prediction rates across groups. This can be done using the following code:
mitigator = ExponentiatedGradient( estimator=LogisticRegression(), constraints=DemographicParity() ) mitigator.fit(X_train, y_train, sensitive_features=s_train) y_pred_mitigated = mitigator.predict(X_test)
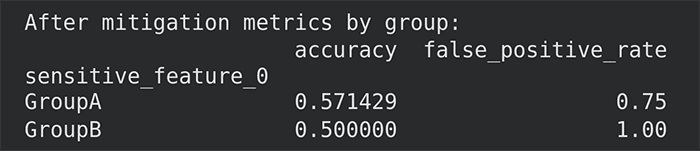
The model is then retrained with access to the sensitive feature, allowing it to explicitly account for group membership while optimising under the fairness constraint. We then generate predictions from this mitigated model to see how its behaviour compares with the baseline. We can do this using the following code and the results would look like what’s shown in Figure 2.
metrics_mitigated = MetricFrame(
metrics={“accuracy”: accuracy_score, “false_positive_rate”: false_positive_rate},
y_true=y_test,
y_pred=y_pred_mitigated,
sensitive_features=s_test
)
print(“\nAfter mitigation metrics by group:”)
print(metrics_mitigated.by_group)
Looking at the baseline results, we can see that the model behaves differently across the two groups. While accuracy is already uneven, the most striking issue is the false positive rate: both GroupA and GroupB have a false positive rate of 1.0, which means every negative example is incorrectly classified as positive. This is a clear signal that the baseline model is not just unfair, but also poorly calibrated for this dataset.
After applying demographic parity through in-processing mitigation, the results improve, at least for one group. GroupA sees a noticeable boost in accuracy (from 0.43 to 0.57) and a reduction in false positive rate (from 1.0 to 0.75). GroupB’s accuracy stays the same, while its false positive rate remains unchanged at 1.0.
This highlights a key reality of fairness interventions: mitigation can reduce disparities, but it often comes with trade-offs and uneven gains across groups. Fairness constraints like demographic parity don’t guarantee perfect balance or better performance everywhere, especially on small or noisy datasets. Instead, they provide a structured way to make bias visible and to reason explicitly about which kinds of fairness we care about, and which costs we’re willing to accept.
In practice, this kind of analysis is less about finding a ‘perfectly fair’ model and more about making informed, transparent decisions about model behaviour before deployment.
This is just the beginning of your journey in responsible AI but can be a strong base for you to explore further and learn more in this field.



{kind=link}