






























































The machine learning-driven approach to enterprise fraud detection outlined here leverages behavioural digital fingerprinting to trace fraudulent activity across large scale systems.
Enterprise digital platforms process millions of interactions daily across geographically distributed users, devices, and services. This scale has made fraud prevention increasingly complex. Modern fraud is rarely isolated to a single account or transaction; instead, it manifests as coordinated activity spanning multiple identities, devices, and sessions.
Traditional rule-based fraud detection systems rely on static thresholds and predefined patterns. While effective against known threats, these approaches struggle in environments where attackers continuously adapt their techniques. Automated scripts can mimic legitimate traffic, rotate IP addresses, and distribute activity to evade detection. As enterprises grow, the limitations of rigid rules become more pronounced, leading to increased false positives, missed fraud, and operational inefficiencies.
To address these challenges, organisations are increasingly turning to machine learning-based approaches capable of identifying subtle behavioural patterns and adapting to evolving threat landscapes.
Fundamental reasons why detection fails on a large scale
Several factors contribute to the failure of conventional fraud detection in large systems.
Distributed attacker operations:
Fraudsters rarely operate from a single machine or in isolation. Instead, they work across fleets of devices, accounts, and identities, making siloed detection ineffective.
Long-term resource procurement:
Fraud actors often acquire infrastructure such as machines, domains, and accounts well in advance and reuse them over extended periods, allowing slow-moving campaigns to evade short term anomaly detection.
Human-like automation:
With advancements in AI, automated agents increasingly mimic human interaction patterns, reducing the effectiveness of simple bot-detection heuristics.
Static assumptions:
Rule-based systems assume predictable attacker behaviour, which is rarely the case in modern fraud operations.
Signal fragmentation:
Fraud indicators are often distributed across systems, devices, and time, making correlation difficult.
Adversarial obfuscation:
Attackers intentionally manipulate surface-level signals such as IP addresses or device identifiers.
Volume and velocity:
Highthroughput environments generate more data than manual or static systems can effectively analyse.
These issues create blind spots that sophisticated attackers exploit, necessitating detection mechanisms that adapt dynamically and reason probabilistically.
Solution overview
The solution proposed here is an enterprise-grade fraud prevention platform that combines client-side behavioural signal capture, scalable backend processing, and AI/ML-driven decisioning. The system integrates:
- Front-end instrumentation to capture behavioural and digital fingerprinting signals;
- Backend APIs to securely collect, normalise, and correlate interaction data;
- Machine learning models, pretrained on historical fraud and abuse patterns, to generate real-time risk assessments.
Together, these components enable proactive and adaptive fraud mitigation across large-scale environments.
Multi-layered fraud mitigation approach
The system mitigates fraud through three complementary mechanisms:
Prevention (pre-entry risk assessment):
The platform continuously evaluates the probability that the individual interacting with the system is a fraudulent actor based behavioural and fingerprinting signals. When risk thresholds are exceeded, access can be restricted or additional controls can be enforced, preventing fraudsters from entering the ecosystem before damage occurs.
Detection and correlation (postentry analysis):
When fraudulent activity is identified within the ecosystem, the system leverages digital fingerprinting to trace related activity across users, devices, and sessions. For example, in cases of identity impersonation, the platform can:
- Identify all device identifiers previously used by the suspect account;
- Correlate those devices with other user accounts;
- Flag related transactions and activities for further investigation.
This correlation capability enables the discovery of coordinated or longrunning fraud campaigns rather than isolated incidents.
Continuous learning and self-correction:
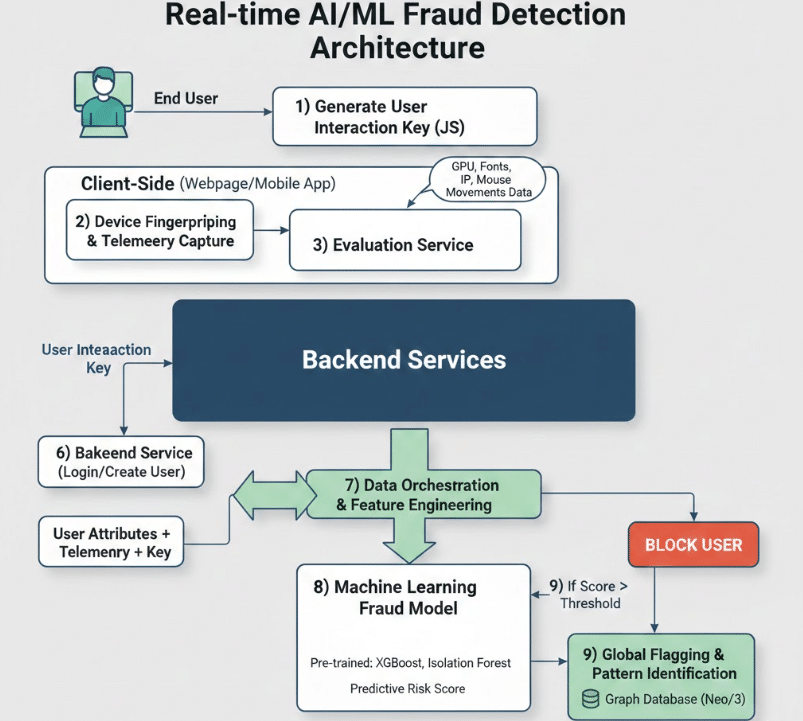
The solution incorporates feedback mechanisms to handle false positives and evolving fraud patterns. Verified outcomes and supporting evidence can be fed back into the system, allowing models to retrain and adapt over time. This continuous learning loop improves accuracy, reduces unnecessary friction for legitimate users, and ensures the system evolves alongside emerging attack techniques. Figures 1 and 2 give the solution workflow and architecture.
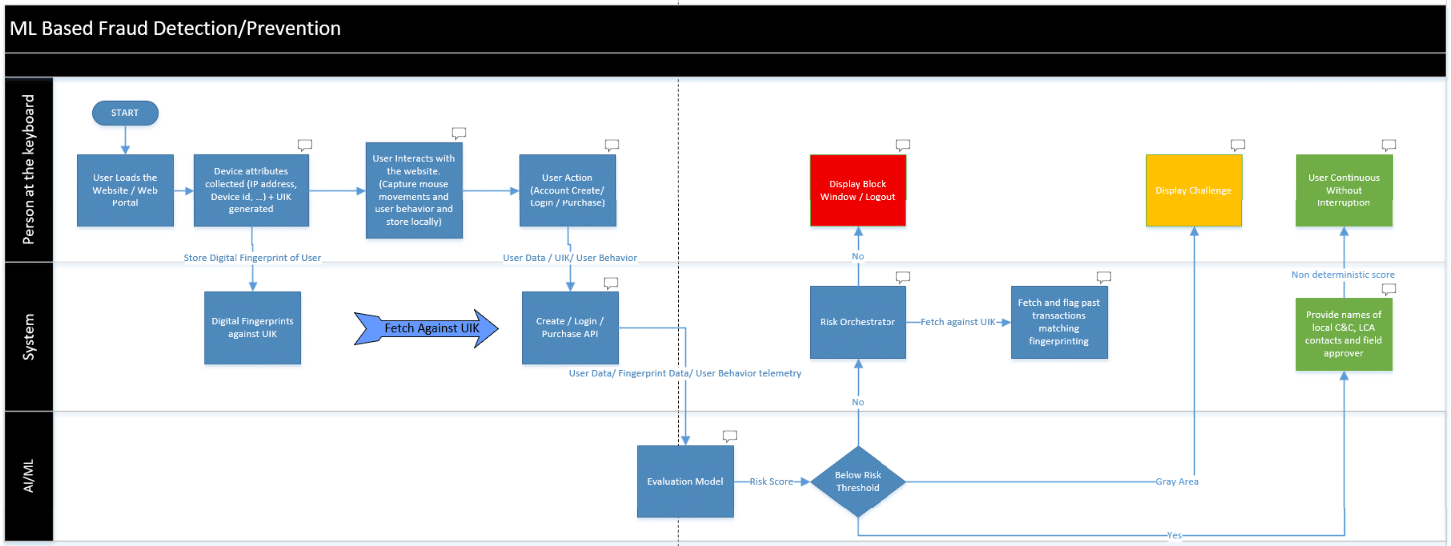
Phase I: Client-side session initialisation
-
Step 1: Unique session anchoring:
Upon page load, a unique User Interaction Key (UIK) is generated to serve as the primary correlation ID across the entire lifecycle of the session.
-
Step 2: Passive device fingerprinting:
A JavaScript-based agent executes on the client side to capture unique hardware and software identifiers (e.g., GPU rendering, canvas fingerprinting, system fonts) to establish a distinct device profile.
-
Step 3: Preliminary identity sync:
The initial device fingerprint and the UIK are transmitted to a backend evaluation service to
establish a baseline for the user’s technical environment.
Phase II: Behavioural telemetry and interaction
-
Step 4: Continuous behavioural monitoring:
The system captures high-fidelity telemetry, including mouse trajectories, click patterns,
and keystroke dynamics, which are buffered locally to build a behavioural biometric profile.
-
Step 5: Event-driven triggers:
The user initiates a critical action (e.g., account registration, authentication, or high-value downloads), serving as the catalyst for a risk evaluation.
- Step 6: Payload aggregation and transmission:
The system bundles identity attributes (PII/form data) with the behavioural telemetry and the UIK, forwarding the unified payload to the relevant application API.
Phase III: Intelligent analysis and enforcement
-
Step 7: Multi-source data fusion:
The backend API retrieves the stored device fingerprint and merges it with the behavioural and identity data, using the UIK as the join key to create a comprehensive feature vector.
-
Step 8: Machine learning inference:
This consolidated data is passed to a pre-trained predictive fraud model (e.g., XGBoost or Neural Network) to calculate a real-time risk score.
-
Step 9: Automated mitigation and global flagging: Real-time enforcement:
If the risk score exceeds the predefined threshold, the transaction is immediately blocked.
- Retrospective analysis: The system performs a graphbased lookup to identify and flag historical activities or accounts associated with the same digital fingerprint, neutralising the fraud network at scale.
Behavioural digital fingerprinting as a detection strategy
Behavioural digital fingerprinting focuses on how interactions occur rather than who initiates them. Instead of relying solely on identity-centric signals, this approach analyses
behavioural characteristics that are difficult to forge consistently at scale.
Examples of behavioural signals include:
- Keyboard interaction timing and cadence
- Navigation sequences and input patterns
- Request frequency and temporal distributions
- Cross-session behavioural consistency
When aggregated, these signals form behavioural fingerprints that capture interaction patterns unique to humans or automated systems. Unlike traditional identifiers, behavioural traits are harder to spoof consistently across devices and sessions, making them valuable for fraud detection.
Feature engineering from low level interaction signals
Raw behavioural data is noisy and highdimensional. Effective fraud detection requires transforming these signals into meaningful features that machine learning models can interpret.
Key feature categories include:
- Temporal features: Inter-keystroke intervals, session duration variability, and response timing distributions
- Consistent features: Repeated behavioural patterns across sessions or devices
- Entropy measures: Variability in input behaviour that distinguishes scripted automation from natural human interaction
- Correlation features: Similarity scores between behaviours observed across different identities or machines
Feature engineering plays a critical role in preserving discriminatory power while reducing dimensionality. Poorly designed features can introduce bias or reduce model effectiveness, particularly in adversarial environments.
Machine learning models for fraud probability scoring
Rather than producing binary decisions, modern enterprise fraud systems typically generate probabilistic risk scores. These scores reflect the likelihood that observed activity is fraudulent based on learned behavioural patterns. Commonly applied model types
include:
- Gradient-boosted decision trees for structured behavioural features
- Ensemble models combining multiple signal sources
- Anomaly detection models to surface previously unseen patterns
By producing probabilistic outputs, these models enable downstream systems to apply risk-based controls— such as step-up authentication or transaction throttling—rather than blunt blocking mechanisms.
Correlating activity across users, devices, and sessions
One of the most powerful capabilities of machine learning-driven fraud detection is cross entity correlation. Fraud rarely occurs in isolation; attackers reuse infrastructure, automation frameworks, and behavioural templates.
Correlation techniques include:
- Graph-based linking of entities through shared behavioural attributes
- Clustering models that identify coordinated activity groups
- Temporal analysis to detect staged or slow-burn attacks
These methods allow enterprises to detect fraud campaigns rather than isolated incidents, significantly improving detection accuracy and response effectiveness.
Distinguishing human behaviour from automation
A core objective of behavioural analysis is distinguishing legitimate human interaction from bot-driven activity. While surface-level signals can be spoofed, behavioural characteristics often reveal automation through:
- Unnaturally consistent timing
- Low entropy in interaction patterns
- Repeated behavioural signatures across unrelated accounts
Machine learning models trained on these characteristics can detect automation even when attackers intentionally mask traditional indicators. This capability is particularly valuable in environments where bots are designed to evade standard detection methods.
Architectural considerations for large-scale deployment
Deploying behavioural fraud detection at enterprise scale requires careful architectural planning. Key considerations include:
- Low-latency inference to avoid degrading user experience
- Horizontal scalability to handle traffic spikes
- Data pipeline reliability for consistent feature generation
- Model lifecycle management to support continuous retraining
Systems must be designed to operate under real-world constraints, including partial data availability and evolving threat patterns.
Privacy, ethics, and responsible use
Behavioural analysis introduces important privacy considerations. Enterprises must ensure that data collection and processing comply with applicable regulations and ethical standards.
Best practices include:
- Minimising data retention
- Avoiding personally identifiable information when possible
- Applying transparency and governance controls
- Evaluating models for unintended bias
Responsible deployment is essential for maintaining user trust while achieving security objectives.
Integrating behavioural fraud detection into enterprise systems
Machine learning-based fraud detection is most effective when integrated as part of a broader risk management strategy.
Integration points may include:
- Authentication workflows
- Transaction risk engines
- Monitoring and alerting systems
By embedding probabilistic fraud signals into decision pipelines, organisations can apply proportional controls that balance security, usability, and operational cost.
Call to action
As fraud tactics continue to evolve, enterprises must move beyond static detection methods. Behavioural digital fingerprinting combined with machine learning offers a scalable, adaptive approach to identifying fraud across complex systems.
Organisations should evaluate their current detection strategies, invest in robust feature engineering, and adopt probabilistic risk models that reflect modern threat realities. By doing so, enterprises can strengthen security posture while preserving trust and user experience.
















