






























































Understanding inodes can be invaluable for troubleshooting disk-space issues, optimising filesystem performance, and recovering deleted files.
An inode (short for ‘index node’) is the link between a file name and its physical location on a storage device. In the UNIX and Linux operating systems, inodes are data structures used to hold metadata about files and directories. A filesystem is how an operating system organises and stores files on a storage device. Each filesystem on the computer has its own separate set of inodes. In short, each filesystem mounted on a computer has its inodes, which are stored in a common table. An inode number can be used more than once but not by the same filesystem. The filesystem ID is paired with the inode number to create a unique identification label.
When a filesystem is created, a fixed number of inodes is created. Typically, approximately 1% of the filesystem disk space is allocated to the inode table. Each file and directory in a filesystem is assigned a unique inode, which is identifiable by an integer known as the inode number. A filesystem is typically separated into inodes and data blocks.
The directory is implemented as a table that maps the filenames to inode numbers. Every file in a directory table is an entry with a filename and inode numbers. All other information about the file is obtained by referencing the inode number in the inode table. When a file is opened, the operating system uses the inode’s pointers to navigate through the disk and retrieve the file content from its physical location. This process is seamless for users but relies heavily on these ‘directions’ stored in the inodes.
Metadata in inodes
Inodes store various types of metadata (as indicated below) about a file or directory, but do not store the name or actual file data.
File type
The file can be a normal file, a directory, or a symbolic link.
File size
This is the size of the file in bytes.
Ownership
The file owner and the group are determined by their user ID (UID) and group ID (GID).
Permissions
Read, write, and execute permissions for the file define access control.
Timestamps
Inodes record timestamps that provide modification (mtime), last access (atime), and inode change times (ctime).
Data block locations
Data block locations are pointers (addresses) to the physical locations on the disk where file data is stored.
Number of links
This refers to the number of hard links that point to the inode.
By efficiently storing metadata, inodes enable robust file access control mechanisms and facilitate auditing processes essential for maintaining system security and integrity.
Total number of inodes
Every system has numerous inodes, and it is important to be mindful of a few key numbers. Theoretically, the maximum number of inodes is equal to 2^32 (approximately 4.3 billion). This is because of the potential range of the 32-bit unsigned integer data type, which is typically used for storing inode numbers. The number of inodes in a filesystem is determined when it is created (formatted) based on factors such as partition size, desired block size, and filesystem type. Hence, a cap on the number of inodes is established when a filesystem is created. This implies that, even if there is free disk space, there is a possibility of running out of inodes if numerous small files are created.
Filesystems are typically configured with a default ratio of inodes to storage space (e.g., 1 inode per 16KB). The ratio is set when the filesystem is created. If you anticipate storing many very small files, you may choose a different ratio, such as one inode per 4KB, if the filesystem creation tools permit it.
Importance of inodes
- Inodes are essential for the Linux system to manage and access files efficiently. They enable quick retrieval of file metadata and content.
- Inodes manage file metadata by storing information, such as ownership, permissions, and timestamps.
- Inodes enable the system to locate all fragments of a file efficiently, even if these are scattered across different parts of the storage device.
- Multiple hard links can point to the same inode. This allows a file to have multiple names within the same filesystem.
Table 1 shows how you can interact with inodes using Linux commands.
| Command | Description | Usage example |
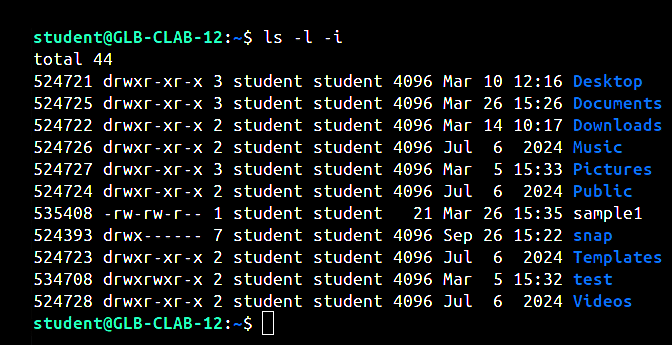
| ls -l -i | The location’s files and directories are listed along with their inode numbers. | ls -l -i |
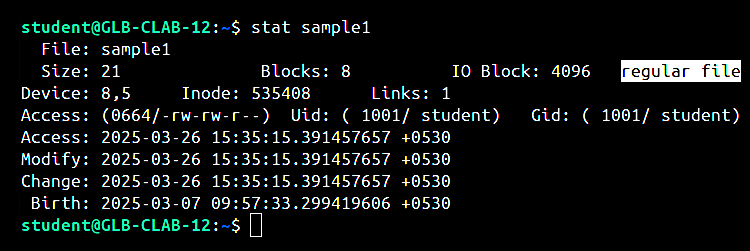
| stat | Displays detailed information about a directory or a file, including its inode number. | stat filename |
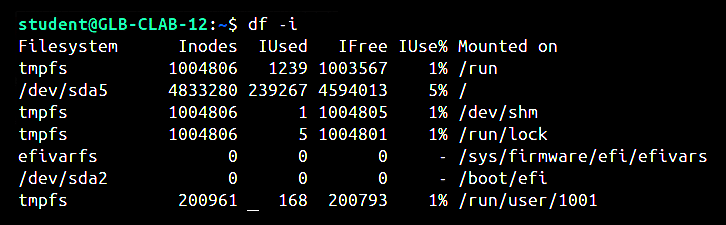
| df -i | Gives inode usage information for all the mounted filesystems, including the total number of inodes and used inodes. | df -i |
| df -hi | Displays the above information in human-readable format | df -hi |
| du –inode | Displays the number of inodes used by files and directories in the current directory. | du –inode |
| find | Searches for files by inode number, and can also execute commands on found files. | find / -inum inode_number -exec rm -i {} \; |
Table 1: Commonly used inode commands
Several commands can be used to operate with inodes on Linux.
ls -l -i: This command shows the inode number of a file or directory in the first column of the output.
stat filename: This command provides detailed information regarding a file, such as its inode number, size, permissions, and timestamps.
df -i: This command displays the total number of inodes, used inodes, and available inodes in a filesystem.
find / -inum inode_number -exec rm -i {} \;: You can use this command to find files based on their inode number.
-exec rm -i {} \;: This part of the command executes the rm (remove) command on each file found. The ‘-i’ option helps remove the file interactively. ‘{}’ is a placeholder for the found filename and ‘\;’ signifies the end of the command to be executed.
The following is an example of finding and removing a file with a specific inode number:
find / -inum 137589 -exec rm -i {}\;
This command searches for a file with inode number 137589 and removes it interactively.
du –inode: This command displays the number of inodes used by files and directories in the current directory.
| Feature | Inode (Linux/UNIX) | MFT (Windows/NTFS) |
| Purpose | Stores file/directory metadata and block location. | Database storing records for all files/directories and their metadata. |
| Identification | Inode number (i-number). | File ID. |
| Metadata storage | Stores permissions, ownership, timestamps,
and block locations. |
Stores permissions (through ACLs), time-stamps, attributes, file size, and data locations. |
| File name storage | Does not store file names; directories map names to inode numbers. | Stores file names within MFT records. |
| Small file handling | Data is stored in data blocks referenced by
the inode. |
Can store small files directly within the MFT record (resident data). |
| Hard links | Supports hard links, where multiple directory entries point to the same inode. | Supports hard links. |
| Architecture | Part of the design of UNIX-like filesystems. | A core database within the NTFS filesystem. |
| Timestamps | Access time (atime), modification time (mtime), change time (ctime). | Creation time, modification time, access time. |
Table 2: A comparison of inodes and MFT
Looking at inode use
One can see how many inodes are in use with the df -i command. This shows the number of inodes taken and free on each filesystem. If the limit on the number of inodes is reached, new files cannot be created even if sufficient disk space is available. This can occur in an email server.
Removing inodes
When a file is deleted, its inode is freed, thus making it available for reuse. A file can also be removed using its inode number, which frees the inode number assigned to the file.
Deleting a file removes the directory entry and frees the inode for reuse; however, data blocks may remain until they are overwritten. Hence, the inode numbers can be used to recover deleted files until they are overwritten.

Key points to note about inodes
- Inodes store metadata about a file but, importantly, do not store the filename or the file’s data. Instead, they contain pointers to the data blocks, i.e., addresses that indicate where the actual file data are stored on the disk where the file’s content resides.
- The number of inodes is set when the filesystem is created. This puts a cap on the number of files that the system can hold.
- Newer file systems, such as JFS, XFS, ZFS, and btrfs, apply flexible inode allocation methods rather than a set-size inode table.
- A filesystem can use all its inodes, even if the disk has space. This occurs when several small files are generated.
Copy and move
When copying a file, the operating system creates a new file. This new file obtains its unique inode number and its own set of data blocks to store file content. This is an entity completely independent of the original entity.

When a file is moved within the same filesystem, the file data and metadata (including the inode number) do not change. Instead, the operating system simply updates the directory entry. Moving a file changes which directory points to the existing inode. The file inode and data remain in the same physical location on the disk. The inode number remains the same.
Copying creates a new file with a new inode, whereas moving updates only the directory information, leaving the inode untouched. If a file is moved to a different filesystem, it involves a copy operation, followed by a delete operation on the original file. Therefore, a new inode is assigned to the file in the destination filesystem.
Inode exhaustion
Inode exhaustion implies that a filesystem no longer has inodes left, even if the disk is not full. This may occur if several small files are created. To fix this, you can find and remove files that are not needed, or, if you can, make more inodes by reformatting the filesystem. Regular cleaning of temporary files, old log files, and unnecessary small files can help to prevent inode exhaustion. Command line tools, such as the ncdu (Ncurses Disk Usage Analyzer), based on the du command, but with an interactive and user-friendly interface, allow users to navigate through directories, sort them by size, and delete unnecessary directories and files directly from the interface.
Implications of inodes
Soft links
When a soft link is created, a new inode is used. Soft links can be created in different filesystems.
Hard links
When creating a hard link, the original file and all its hard links have the same inode number because hard links only provide name a new filename for the same data. The implementation of hard links is possible owing to the inodes. This is also the reason for the inability to create hard links across different filesystems, which may lead to conflicting inode numbers.
The inode’s ‘link count’ field tracks the number of hard links pointing towards it. Deleting only one hard link decreases the link count. The file data is not deleted until all hard links are removed, and the link count reaches zero. Hard links remain valid even if the original file is renamed or moved within the same filesystem because they reference the inode directly rather than a path.
Windows version of inodes
Inodes are unique to UNIX-like filesystems. Windows OS NTFS (New Technology File System) uses a Master File Table (MFT) to track the file details. MFT is a centralised structure that contains records of all files and folders in an NTFS volume.
The MFT combines an inode table and directory structure. Unlike inodes, the MFT stores some of the file’s metadata directly within the MFT entry along with pointers to the data. This can make NTFS faster for small files; however, MFT can become fragmented over time. The MFT stores information about every file and folder in the NTFS volume. This includes size, timestamps, who can access it, and where the data is stored.
The contents of small files and directories (512 bytes or fewer) can be stored directly within the MFT entry. This reduces the need for additional disk reads, making NTFS faster than inode-based systems for accessing small files.
Implementation of inodes in newer filesystems
Dynamic inode allocation
Modern file systems, such as XFS, ZFS, btrfs, and APFS, have moved away from fixed-size inode tables. Instead, they use dynamic allocation methods that allow inodes to be created on demand. This eliminates the risk of running out of the inodes and provides greater flexibility for handling varying file sizes and usage patterns.
Extended metadata
Modern filesystems store additional metadata within inodes or equivalent structures. For example, ZFS includes checksums for data integrity, while btrfs supports advanced features, such as snapshots, cloning, compression, and deduplication.
Inlining
Some newer filesystems (e.g., XFS) support inlinings, where small file data is stored directly within the inode. Inlining allows small files to store their data directly within their inode, instead of using separate data blocks. This reduces the disk I/O and improves the performance of small files. As no additional data blocks are allocated, fragmentation is minimised for inline files, making access faster and more efficient. For files that start small but grow larger over time, inlining systems dynamically move data out of the inode into separate data blocks, as needed. Only very small files can benefit from inlining, owing to space constraints within an inode.
Larger file systems and 64-bit inode numbers
To support larger filesystems with more files, some modern systems use 64-bit inode numbers instead of traditional 32-bit numbers. This expands the theoretical limit of the number of inodes. Some modern filesystems are designed to handle massive storage capacities with billions of files. For example, XFS can support exabytes of storage and ZFS can manage petabytes of data.
Integration with virtual filesystems using Vnodes
In newer operating systems derived from BSD or Linux, inodes are abstracted into ‘vnodes’ (virtual nodes). Vnodes provide a unified interface for file management that supports different filesystems, while retaining backward compatibility with classic inodes.
Inodes are an excellent point to begin if you want to learn about filesystems and their structures. Understanding the categorising and indexing of data units is important for administrators and power users. I hope that this broad overview will provide a basic understanding of inodes. To further learn about filesystems, consider using tools such as debugfs, which can help examine a filesystem’s metadata directly. Experimentation with terminal-based tools can strengthen our understanding of file management. Learning these concepts can assist Linux users and administrators.


















{kind=link}